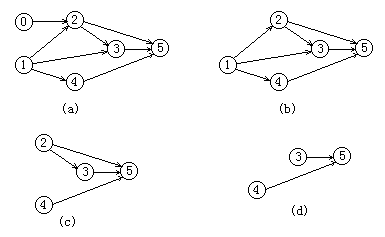
classSolution: # @return a undirected graph node defcloneGraph(self, node): ifnot node:returnNone head=UndirectedGraphNode(node.label) q,vis,dic=[],set([node]),{} dic[node]=head q.append(node) while q: cur = q.pop() for i in cur.neighbors: if i notin dic: dic[i]=UndirectedGraphNode(i.label) dic[cur].neighbors.append(dic[i]) if i notin vis: q.append(i) vis.add(i) return head
classUndirectedGraphNode: def__init__(self, x): self.label = x self.neighbors = []
defprintGraph(node): q ,vis = [],set([node]) q.append(node) while q: cur = q.pop(0) print' ',cur.label for i in cur.neighbors: print i.label if i notin vis: q.append(i) vis.add(i)
s=Solution() one = UndirectedGraphNode(1) two = UndirectedGraphNode(2) three =UndirectedGraphNode(3) one.neighbors.append(one) one.neighbors.append(two) two.neighbors.append(three) #printGraph(one) printGraph( s.cloneGraph(one))
207. leetcode Course Schedule
There are a total of n courses you have to take, labeled from 0 to n - 1.
Some courses may have prerequisites, for example to take course 0 you have to first take course 1, which is expressed as a pair: [0,1]
Given the total number of courses and a list of prerequisite pairs, is it possible for you to finish all courses?
For example:
1
2, [[1,0]]
There are a total of 2 courses to take. To take course 1 you should have finished course 0. So it is possible.
1
2, [[1,0],[0,1]]
There are a total of 2 courses to take. To take course 1 you should have finished course 0, and to take course 0 you should also have finished course 1. So it is impossible.
classSolution { public: boolcanFinish(int numCourses, vector<pair<int, int>>& prerequisites){ vector<vector<int> > g(numCourses); vector<int> in_degree(numCourses, 0); for (int i = 0; i < prerequisites.size(); i++){ g[prerequisites[i].second].push_back(prerequisites[i].first); in_degree[prerequisites[i].first]++; } queue<int> q; for (int i = 0; i < numCourses; i++) if (in_degree[i] == 0) q.push(i); while (!q.empty()){ int cur = q.front(); q.pop(); for (auto it = g[cur].begin(); it != g[cur].end(); it++) if (--in_degree[*it] == 0) q.push(*it); }
for (int i = 0; i < numCourses; i++) if (in_degree[i] != 0) returnfalse; returntrue; } };
210. leetcode Course Schedule II
There are a total of n courses you have to take, labeled from 0 to n - 1.
Some courses may have prerequisites, for example to take course 0 you have to first take course 1, which is expressed as a pair: [0,1]
Given the total number of courses and a list of prerequisite pairs, return the ordering of courses you should take to finish all courses.
There may be multiple correct orders, you just need to return one of them. If it is impossible to finish all courses, return an empty array.
For example:
1
2, [[1,0]]
There are a total of 2 courses to take. To take course 1 you should have finished course 0. So the correct course order is [0,1]
1
4, [[1,0],[2,0],[3,1],[3,2]]
There are a total of 4 courses to take. To take course 3 you should have finished both courses 1 and 2. Both courses 1 and 2 should be taken after you finished course 0. So one correct course order is [0,1,2,3]. Another correct ordering is[0,2,1,3].
classSolution { public: vector<int> findOrder(int numCourses, vector<pair<int, int>>& prerequisites){ vector<vector<int> > g(numCourses); vector<int> in_degree(numCourses, 0); vector<int> ans; for (int i = 0; i < prerequisites.size(); i++){ g[prerequisites[i].second].push_back(prerequisites[i].first); in_degree[prerequisites[i].first]++; } queue<int> q; int cnt = 0; for (int i = 0; i < numCourses; i++) if (in_degree[i] == 0) q.push(i); while (!q.empty()){ int cur = q.front(); ans.push_back(cur); q.pop(); for (auto it = g[cur].begin(); it != g[cur].end(); it++) if (--in_degree[*it] == 0) q.push(*it); }
有 n 个城市,其中一些彼此相连,另一些没有相连。如果城市 a 与城市 b 直接相连,且城市 b 与城市 c 直接相连,那么城市 a 与城市 c 间接相连。
省份 是一组直接或间接相连的城市,组内不含其他没有相连的城市。
给你一个 n x n 的矩阵 isConnected ,其中 isConnected[i][j] = 1 表示第 i 个城市和第 j 个城市直接相连,而 isConnected[i][j] = 0 表示二者不直接相连。
返回矩阵中 省份 的数量。
示例 1:
img
1 2
>输入:isConnected = [[1,1,0],[1,1,0],[0,0,1]] >输出:2
示例 2:
img
1 2
>输入:isConnected = [[1,0,0],[0,1,0],[0,0,1]] >输出:3
提示:
1 <= n <= 200
n == isConnected.length
n == isConnected[i].length
isConnected[i][j] 为 1 或 0
isConnected[i][i] == 1
isConnected[i][j] == isConnected[j][i]
方法1:dfs即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
classSolution: def findCircleNum(self, isConnected: List[List[int]]) -> int: vis = [False] * len(isConnected) ans = 0 for i in range(len(isConnected)): if vis[i]: continue ans += 1 vis[i] = True self.dfs(i, isConnected, vis) return ans def dfs(self, cur, isConnected, vis): row = isConnected[cur] for i in range(len(row)): if row[i] andnot vis[i]: vis[cur] = True self.dfs(i, isConnected, vis)
方法2: 并查集
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
classSolution: deffindCircleNum(self, isConnected: List[List[int]]) -> int: fa = list(range(len(isConnected))) for i inrange(len(isConnected)): for j inrange(i): if isConnected[i][j]: root_x = self.find(i, fa) root_y = self.find(j, fa) if root_x != root_y: fa[root_y] = root_x
returnsum([1if i == fa[i] else0for i inrange(len(isConnected))]) deffind(self, cur, fa): if fa[cur] == cur: return cur fa[cur] = self.find(fa[cur], fa) return fa[cur]
defhitBricks(self, grid: List[List[int]], hits: List[List[int]]) -> List[int]: origin_grid = copy.deepcopy(grid) for x, y in hits: grid[x][y] = 0 self.m, self.n = len(grid), len(grid[0]) roof_key = self.get_key(self.m, self.n) # 屋顶的key unionfind = UnionFind(roof_key + 1) for j inrange(self.n): if grid[0][j] == 1: unionfind.union(self.get_key(0, j), roof_key)
for i inrange(1, self.m): for j inrange(self.n): if grid[i][j] == 0: continue
if grid[i - 1][j]: unionfind.union(self.get_key(i, j), self.get_key(i - 1, j)) if j and grid[i][j - 1]: unionfind.union(self.get_key(i, j), self.get_key(i, j - 1))
ans = [] for x, y in hits[::-1]: if origin_grid[x][y] == 0: ans.append(0) continue
cur_key = self.get_key(x, y) pre_num = unionfind.get_count(roof_key) if x == 0: unionfind.union(cur_key, roof_key) for i inrange(4): nx, ny = x + self.dx[i], y + self.dy[i] if nx < 0or ny < 0or nx >= len(grid) or ny >= len(grid[0]) or \ not grid[nx][ny]: continue unionfind.union(cur_key, self.get_key(nx, ny)) after_num = unionfind.get_count(roof_key) cur = max(after_num - pre_num - 1, 0) ans.append(cur) grid[x][y] = 1 return ans[::-1]
defget_key(self, x, y): return x * self.n + y
classUnionFind(object): def__init__(self, n): self.fa = [i for i inrange(n)] self.counter = [1] * n deffind(self, x): if x != self.fa[x]: self.fa[x] = self.find(self.fa[x]) return self.fa[x]
classSolution { public: intminimumEffortPath(vector<vector<int>>& heights){ if (heights.empty()) return0; constint m = heights.size(); constint n = heights[0].size(); int dx[] = {1, -1, 0, 0}; int dy[] = {0, 0, 1, -1}; int left = 0, right = 1e6 + 1; while (left < right) { int mid = left + ((right - left) >> 1); queue<pair<int, int>> q; vector<vector<bool>> vis(m, vector<bool>(n, false)); q.emplace(0, 0); vis[0][0] = true; while (!q.empty()) { auto [x, y] = q.front(); q.pop(); if (x == m - 1 && y == n - 1) { break; } for (int i = 0; i < 4; ++i) { int nx = x + dx[i]; int ny = y + dy[i]; if (nx < 0 || ny < 0 || nx >= m || ny >= n || vis[nx][ny]) { continue; } if (abs(heights[nx][ny] - heights[x][y]) <= mid) { q.emplace(nx, ny); vis[nx][ny] = true; } } }
if (vis[m - 1][n - 1]) { right = mid; } else { left = mid + 1; } } return left; } };