1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
|
import requests
import urllib
import urllib2
import re
import cookielib
class baiduLogin:
url_token = 'https://passport.baidu.com/v2/api/?getapi&tpl=pp&apiver=v3&tt=1426660772709&class=login&logintype=basicLogin&callback=bd__cbs__hif73f'
url_login = 'https://passport.baidu.com/v2/api/?login'
url_tieba = 'http://tieba.baidu.com/f/like/mylike?v=1387441831248'
s = requests.Session()
def startLogin(self,username,password):
postData = {
'username' : username,
'password' : password,
'token' : self.getToken(),
'charset' : 'UTF-8',
'apiver' : 'v3',
'isPhone' : 'false',
'tpl' : 'pp',
'u' : 'https://passport.baidu.com/',
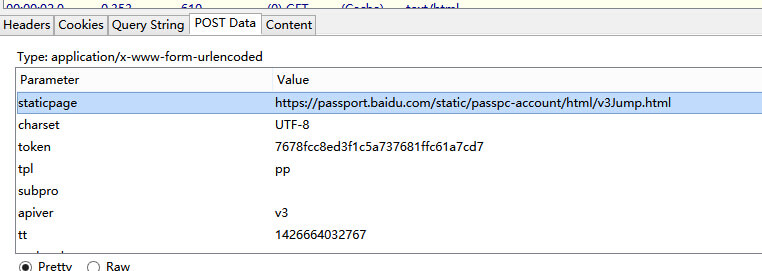
'staticpage' : 'https://passport.baidu.com/static/passpc-account/html/v3Jump.html',
'callback' : 'parent.bd__pcbs__ra48vi'
}
myhead={
'Host': 'passport.baidu.com',
'Referer': 'https://passport.baidu.com/v2/?login',
'Connection': 'keep-alive',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'zh-CN,zh;q=0.8,en;q=0.6',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.115 Safari/537.36' ,
}
self.s.post(self.url_login,data=postData,headers=myhead)
def getToken(self):
r = self.s.get(u'http://www.baidu.com/')
r = self.s.get(self.url_token)
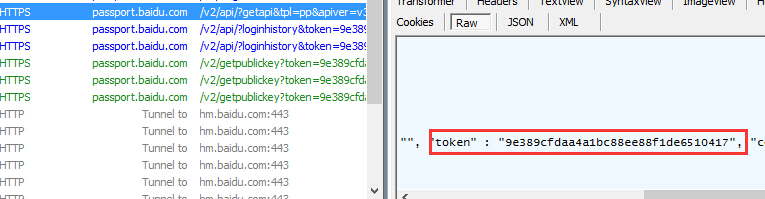
token = re.search(u'"token" : "(?P<token>.*?)"',r.text)
return token.group('token')
def getMyTieBa(self):
tieba = self.s.get(self.url_tieba)
tieba.encoding = 'gbk'
print tieba.text
username = ''
password = ''
baidu = baiduLogin()
baidu.startLogin(username, password)
baidu.getMyTieBa()
|