前阵子有学弟学妹问我毕设做的啥,于是我决定记录一下去年毕设的内容。
主要是基于twitter的内容有:
- 实时热点话题检测
- 情感分析
- 结果可视化
- Twitter数据挖掘平台的设计与实现
毕设、论文内容
毕设从16年3月开始做,做到5月初,开始写论文,当时写的论文一共有七章,写了一个礼拜,从早到晚- - 共24834字。数据有的从15年11月左右开始抓的。导师那时候很忙都没空理我- - 都自己说要做啥然后自己去做。。。。
论文总共有七章,结构安排如下:
第一章,引言。主要介绍了Twitter下进行的数据挖掘的背景,以及国内外研究现状,并简要的说明了本文的主要研究内容。
第二章,Twitter相关的内容介绍。主要介绍Twitter的一些特殊语法,如用户提及@,hashtags等,接着讨论了Twitter中大量存在的拼写错误、缩写、重复字母现象,最后介绍了Twitter的REST API与StreamAPI。
第三章,实时热点话题挖掘。该章节首先介绍了LDA相关的模型,接着提出了WOLDA算法,以及最具有代表性推文的计算方法。
第四章,情感分析。该章节介绍了Twitter下的情感分析分类、以及机器学习的一般过程,接着介绍本文使用机器学习和情感词典相结合的方法。
第五章,数据可视化。介绍了几种基于统计的可视化方法,还有主题分析和情感分析的可视化的方法,可以更直观的表示结果。
第六章,Twitter数据挖掘平台的设计与实现。结合了前面几章的内容,介绍实现该系统的细节。
第七章总结了本文的工作,针对目前的不足,提出下一步改进的方案。
本篇博文为缩减版,除了略去一二章外,其它章节也做了精简。
实时热点话题挖掘
Twitter从2006年以来,发展迅猛。举两个数据来讲,
- 2015年5月,Twitter拥有超过5亿的用户,其中有超过3.32亿的活跃用户
- 2016年2月28日莱昂纳多获得第88届奥斯卡最佳男主角奖时,据统计,这一消息在Twitter上的讨论达到每分钟44万次
可以看出,Twitter的数据量是十分庞大的。为了能够了解Twitter上人们在谈论些什么,我们希望能够有一种有效的方 式来获取 Twitter 实时的热点话题。要求该方式:
- 能处理流数据并且对模型进行周期性的更新 。
- 产生的主题 与过去的 主题有关联 以便 观测话题的演变 。
- 资源占用稳定,不随时间增大而以便保证效率和对新话题的敏感 。
LDA模型
首先想到的就是主题模型。
2003年,D.Blei等人提出了广受欢迎的LDA(Latentdirichlet allocation)主题模型[8]。LDA除了进行主题的分析外,还可以运用于文本分类、推荐系统等方面。
LDA模型可以描述为一个“上帝掷骰子”的过程,首先,从主题库中随机抽取一个主题,该主题编号为K,接着从骰子库中拿出编号为K的骰子X,进行投掷,每投掷一次,就得到了一个词。不断的投掷它,直到到达预计的文本长度为止。简单的说,这一过程就是“随机的选择某个主题,然后从该主题中随机的选择词语”。按照之前的描述,一篇文档中词语生成的概率为:
\[ p(词语文档) = \sum_{主题} (p(词语主题)·p(主题文档)) \] 可以用矩阵的乘法来表示上述的过程:
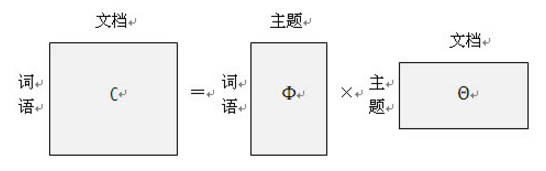
回到LDA模型来说,LDA模型的输入是一篇一篇用BOW(bag of words)表示的文档,即用该文档中无序的单词序列来表示该文档(忽略文档中的语法和词语的先后关系)。LDA的输出是每篇文档的主题分布矩阵和每个主题下的单词分布矩阵。简而言之,LDA主题模型的任务就是已知左边的矩阵,通过一些方法,得到右边两个小矩阵。这里的“一些方法”即为LDA采样的方法,目前最主要的有两种,一种是变分贝叶斯推断(variationalBayes, VB),另一种叫做吉布斯采样(Gibbs Sampling),其中吉布斯采样也被称为蒙特卡洛马尔可夫 (Markov Chain Monte Carlo,MCMC)采样方法。
总的来说,MCMC实现起来更加简单方便,而VB的速度比MCMC来得快,研究表明他们具有差不多相同的效果。所以,对于大量的数据,采用VB是更为明智的选择。
Hoffman OLDA
虽然VB的速度相对而言比较快,但是对于巨大的数据来说,VB计算量仍十分巨大的,对此,Hoffman提出了Online variational Bayes (VB)算法(下面简称为OLDA),将数据集其分为一些小的batch, 然后更新,运算速度得到了巨大的提升。

WOLDA
虽然Hoffman提出的OLDA算法可以对后加进来的文档不断的更新,但是,该算法仍不能称得上是在线的算法。原因如下:
- 该算法采用静态词库(忽略不在词库中的词),而对于Twitter来说,新词不断涌现,缩写词、网络流行语、特殊事件人名、地名频繁出现,基本无法预测。即使我们拥有一个囊括了所有词的词库,那么这个词库也必然是巨大的,造成矩阵过于稀疏,运算效率低下。
- OLDA算法对旧话题“淡忘”速度越来越慢。如果一开始出现了所谓的“离题”(topic drift)现象,结果将会十分差劲,这不利于新话题的检测。
为此,改进的算法命名为WOLDA。
WOLDA采用动态的词库,(滑动时间窗口)
- 时间分为一个个时间片
- 只保留时间窗口L内的词 && 词频 > min_df(预设值)
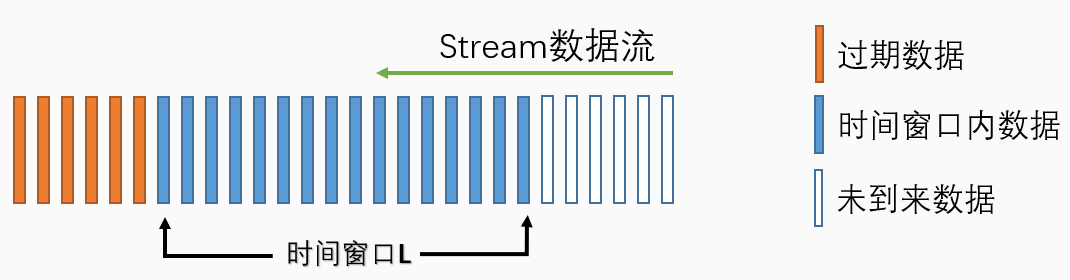
对于1~L个时间片,对词频不小于min_df的词作为当前WOLDA的词库。
第L+1个时间片到来时,删除第1个时间片的文档,对第2个到第L+1个时间窗口内的文档重新计算词频,并将词频不小于min_df的词作为当前WOLDA的词库。
模型的更新方法为,对于新词,进行随机的初始化,而对于原本存在词库中的词有:
\[ \lambda = C * \lambda \] 贡献因子C使得模型具有事件演变的能力,它将连续时间切片上的前后模型相结合。在具体的实现上,对于给定贡献因子C,我们只需要反解出OLDA中的更新次数t,将OLDA的更新次数重新设置为t即可,公式如下: \[ t = (1-C)^{-\frac{1}{\kappa}}-\tau_0 \] 此外,还需要更新OLDA相应参数,如单词总数W和文档长度D。
算法描述如下:
1 | 定义窗口大小 L,贡献因子c,最小的词频 min_df |
最具有代表性的推文计算
运行WOLDA算法后,我们得到了每个主题下对应的主题词,主题词有时候对于主题的描述不够直观,为此我们希望从该主题下,能找到最具有代表性的推文,用来帮助解释和说明该主题的内容。本小节提出几种最具有代表性的推文的计算方法,并在之后的实验中加以对比。
KL-mean
KL散度(Kullback–Leibler divergence)又称为相对熵(relative entropy),它可以用来衡量两个概率分布的相似程度。对于离散型的随机变量,其概率分布P和Q的KL散度定义如下:
\[ D_{KL}(PQ) = \sum_iP(i) ln\frac{P(i)}{Q(i)} \]
通常情况下KL散度是非对称的,因此这里采用KL-mean方式(求P和Q KL散度以及Q和P KL散度的均值)
\[ D_{KL-mean}(PQ) = \frac{1}{2}(D_{KL}(PQ) +D_{KL}(QP) ) \]
使用KL-mean距离计算最具有代表性的推文伪代码如下:
1 | pro_matrix: 主题-单词矩阵 |
余弦距离
余弦距离常常用来衡量相似度(通过计算两个向量夹角的余弦值)。其定义如下:
\[ D_{cos}(P,Q) = \frac{P·Q}{P·Q} \]
使用余弦距离计算最具有代表性的推文的方法与KL散度的方法过程类似,只不过最后采用了余弦距离来计算每条推文与其主题中心的距离。
最大熵
在信息学中,熵(Entropy)常常被用来衡量信息不确定度的大小,信息的不确定度,表明其信息量也越大,同时熵也越大。熵的计算公式如下:
\[ Entropy(X) = -\sum_iP(x_i)log_2P(x_i) \]
1 | p: 主题-单词矩阵 |
情感分析
为什么要进行情感分析?Twitter的作为一个微博客服务,它的推文中又充斥着大量的观点见解,进行情感分析也同样具有广阔的应用场景,比如说以下的这个方面:
- 情感分析可以帮助用户做出是否购买的决策。例如,消费者在犹豫是否购买产品时,会很自然的去查看其他人对于该商品的评价。如果“好评”居多,该消费者可能就会进行购买;反之,如果“差评”占大多数,那么该消费者一般而言就不会进行购买了。如果能针对Twitter这种既有强时效性又有广泛话题领域的社交媒体进行情感分析,那将给用户带来更多的便利。
- 情感分析还可以帮助企业进行市场调研。企业在推出一款新的产品之后,可以通过情感分析来从大量的用户评价中得到有用的信息,如用户喜欢什么,不喜欢哪一方面,对公司的产品和服务有哪些正面或负面的影响。从而企业可以了解自身的优势和不足,可以更好的制定相应的措施进行服务的改进,从而在激烈的市场竞争中占据主动地位。
- 舆情监控。由于用户可以在社交媒体上相对自由的发表自己的观点,这使得社交媒体成为了舆情话题产生和传播的重要方式。通过对社交媒体的情感分析,可以为政府了解民意、引导舆论提供有效的工具。对于负面的消息,可以较为及时的安抚好民众的情绪,避免事态进一步恶化。同时,政府也可以制定相应的策略来改善现有的服务。
- 事件预测。随着互联网发展,越来越多的民众愿意到网上发表自己对某一事件的看法,无论是在诸如Twitter、新浪微博这样的微博客,还是在贴吧、知乎等站点上。一个典型的例子就是最近阿里人工智能运用神经网络、情绪感知等技术对《我是歌手》第四季总决赛的歌王进行了成功的预测。此外,Twitter这一个平台也常常被拿来预测选举、股票等。
情感分析方法
本文采用的情感分析可以说是一个标准的机器学习的分类问题。
目标是给定一条推文,将其分为正向情感、负向情感、中性情感。
预处理
POS标注
- CMU ArkTweetNLP
字母连续三个相同
- 替换 “coooooooool”=>“coool”
删除非英文单词
删除URL
删除@
- 删除用户的提及@username
删除介词、停止词
否定展开
- 将以"n't"结尾的单词进行拆分,如"don't" 拆分为"do not",这里需要注意对一些词进行特殊处理,如"can't"拆分完之后的结果为"can not",而不是"ca not"。
否定处理
- 从否定词(如shouldn't)开始到这个否定词后的第一个标点(.,?!)之间的单词,均加入_NEG后缀。如perfect_NEG。 “NEG”后缀
特征提取
文本特征
N-grams
- 1~3元模型
- 使用出现的次数而非频率来表示。不仅是因为使用是否出现来表示特征有更好的效果[16],还因为Twitter的文本本身较短,一个短语不太可能在一条推文中重复出现。
感叹号问号个数
- 在句子中的感叹号和问号,往往含有一定的情感。为此,将它作为特征。
字母重复的单词个数
- 这是在预处理中对字母重复三次以上单词进行的计数。字母重复往往表达了一定的情感。
否定的个数
- 否定词出现后,句子的极性可能会发生翻转。为此,把整个句子否定的个数作为一个特征
缩写词个数等
POS 标注为[‘N’, ‘V’, ‘R’, ‘O’, ‘A’] 个数(名词、动词、副词、代词、形容词)
词典特征(本文使用的情感词典有:Bing Lius词库[39]、MPQA词库[40]、NRC Hashtag词库和Sentiment140词库[42]、以及相应的经过否定处理的词库[45])
- 推文中的单词在情感字典个数 (即有极性的单词个数)
- 推文的 总情感得分:把每个存在于当前字典单词数相加,到推文的 总情感得分:把每个存在于当前字典单词数相加,到推文的 总情感得分:把每个存在于当前字典单词数相加,到推文总分,这个数作为一特征。
- 推文中单词最大的正向情感得分和负。
- 推文中所有正向情感的单词分数 和以及 所有负向情感单词的分数和。
- 最后一个词的分数
表情特征
- 推文中正向 情感 和负向的表情个数
- 最后一个表情的极性是 否为正向
特征选择
本文 特征选择主要是针对于 N-grams 特征 的,采用方法如下:
1 | 设定min_df(min_df>=0)以及threshold(0 <= threshold <= 1) |
上述算法中滤除了低频的词,因为这可能是一些拼写错误的词语;并且,删除了一些极性不那么明显的词,有效的降低了维度。
分类器选择
在本文中,使用两个分类器进行对比,他们均使用sklearn提供的接口 。第一个分类器选用SVM线性核分类器,参数设置方面,C = 0.0021,其余均为默认值。第二个分类器是Logistic Regression分类器,其中,设置参数C=0.01105。
在特征选择上,min_df=5, threshold=0.6。
实验
- SemEval(国际上的一个情感分析比赛)训练数据和测试数据
- 评价方法采用F-score
- 对比SemEval2016结果如下
测试集名
| 测试集名 | SVM(F-score/Rank) | Logistic Regression(F-score/Rank) |
|---|---|---|
| 2013 Tweet | 0.701 / 5 | 0.714 / 3 |
| 2013 SMS | 0.719 / 1 | 0.722 / 1 |
| 2014 Tweet | 0.693 / 8 | 0.692 / 8 |
| 2014 Tweet sarcasm | 0.478 / 6 | 0.478 / 6 |
| 2014 Live Journal | 0.712 / 4 | 0.726 / 2 |
数据可视化
为什么要进行数据可视化呢?因为可以更快速、更轻松的提取出数据的含义。例如
将3标注为红色容易找出所有的3
-
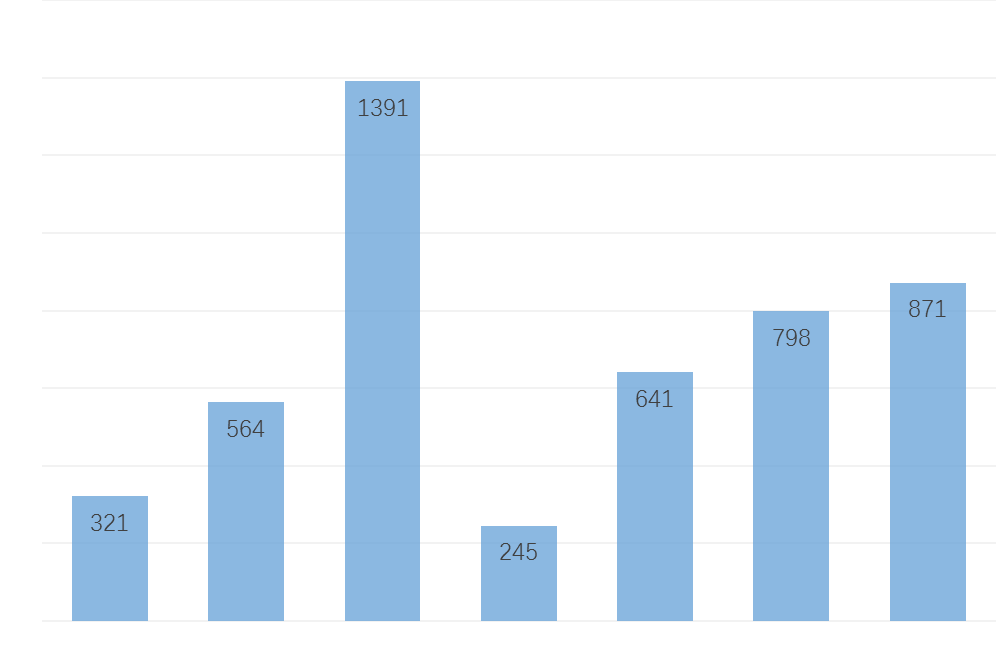
画柱状图容易找数组【 321, 564, 1391, 245, 641, 798,871 】中的最大值
简单的统计结果可视化
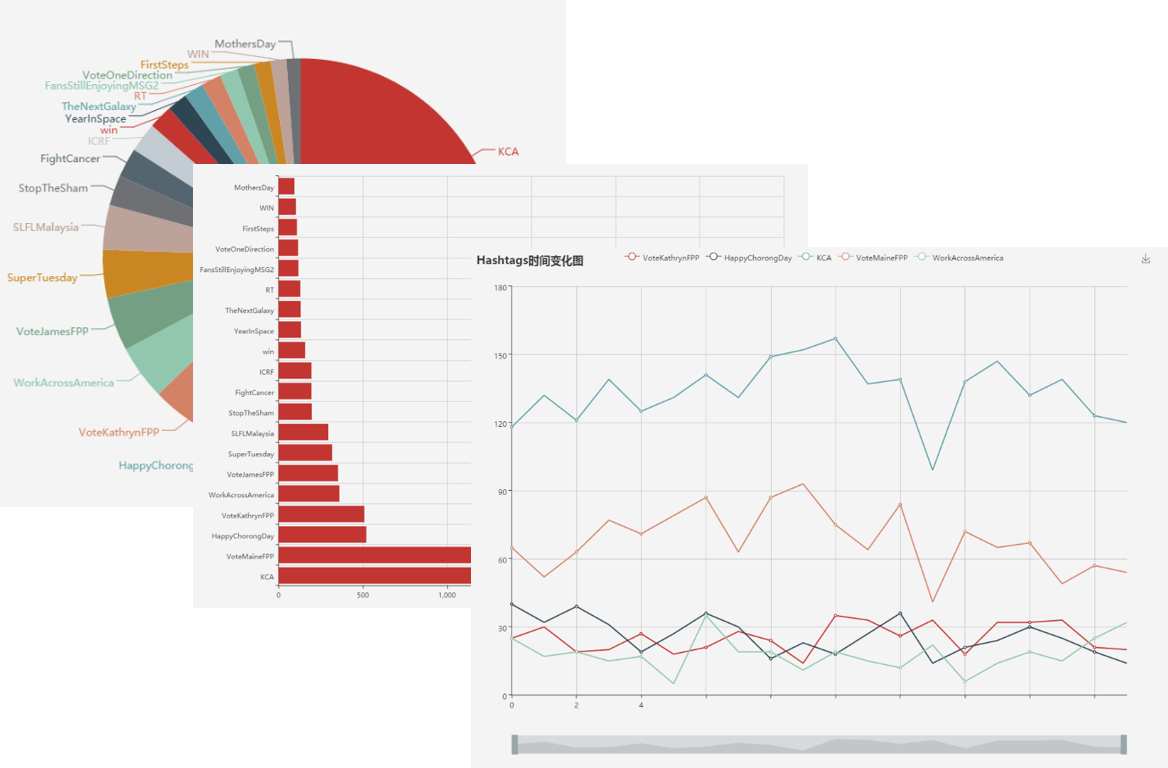
Hashtag统计
由于Hashtag是用户手动添加的、用来表明当前发表的推文的主题。因此对其进行统计,然后进行可视化也是具有一定意义的。简单的说,进行hashtag统计的可以有柱状图、饼状图、趋势图三种方法。
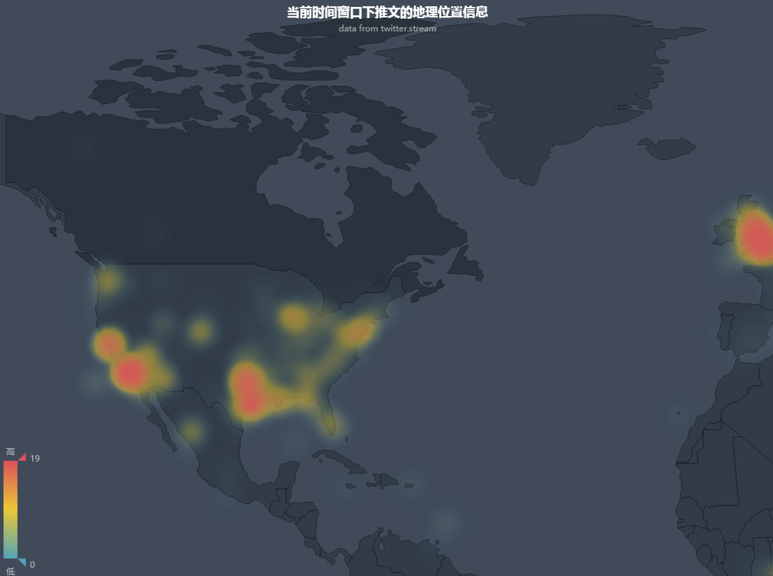
地理位置信息的可视化
Twitter的API返回字段中,有几个字段是和地理位置相关的,用来表示该推文的发表位置,或者某地点和该推文相关。我们可以对地理位置信息进行统计计数。一个可视化的办法就是在地图上根据经纬度坐标画一个个的点,但是当有多个点再一个小区域的时候可读性较差,因此本文使用的是热力图。一个样例图如下:
话题结果可视化
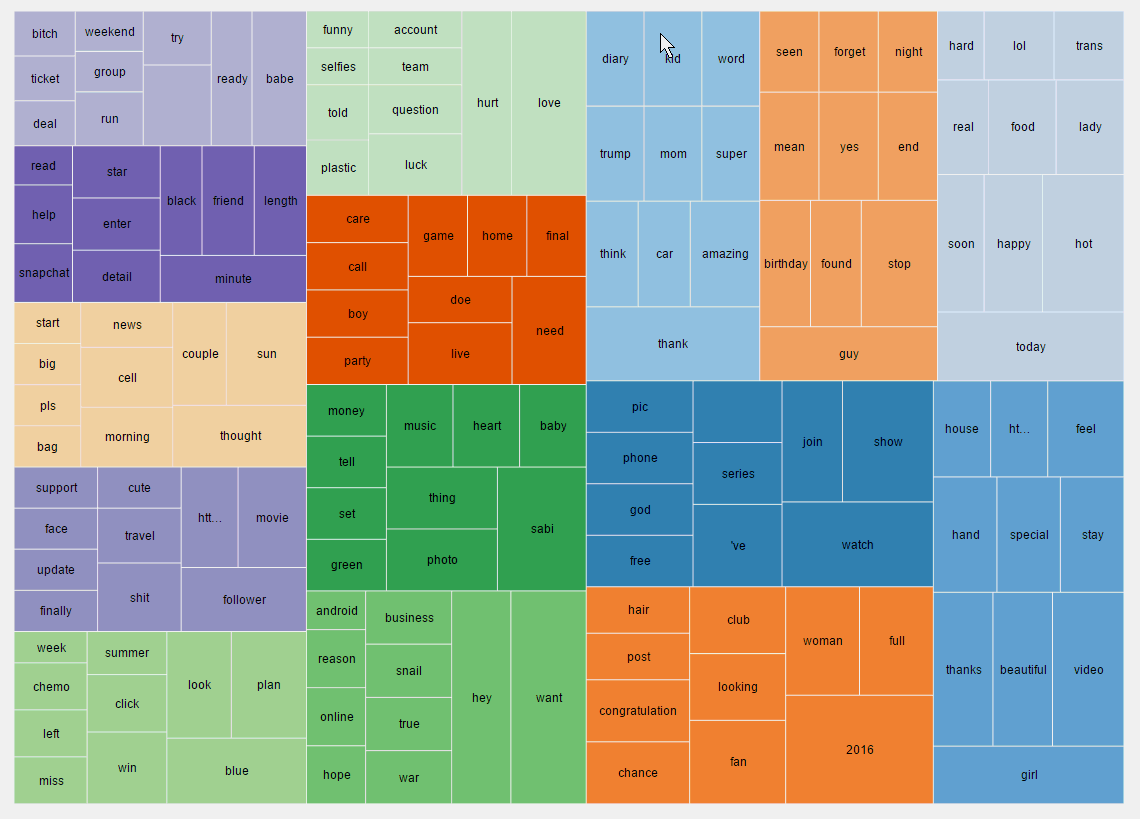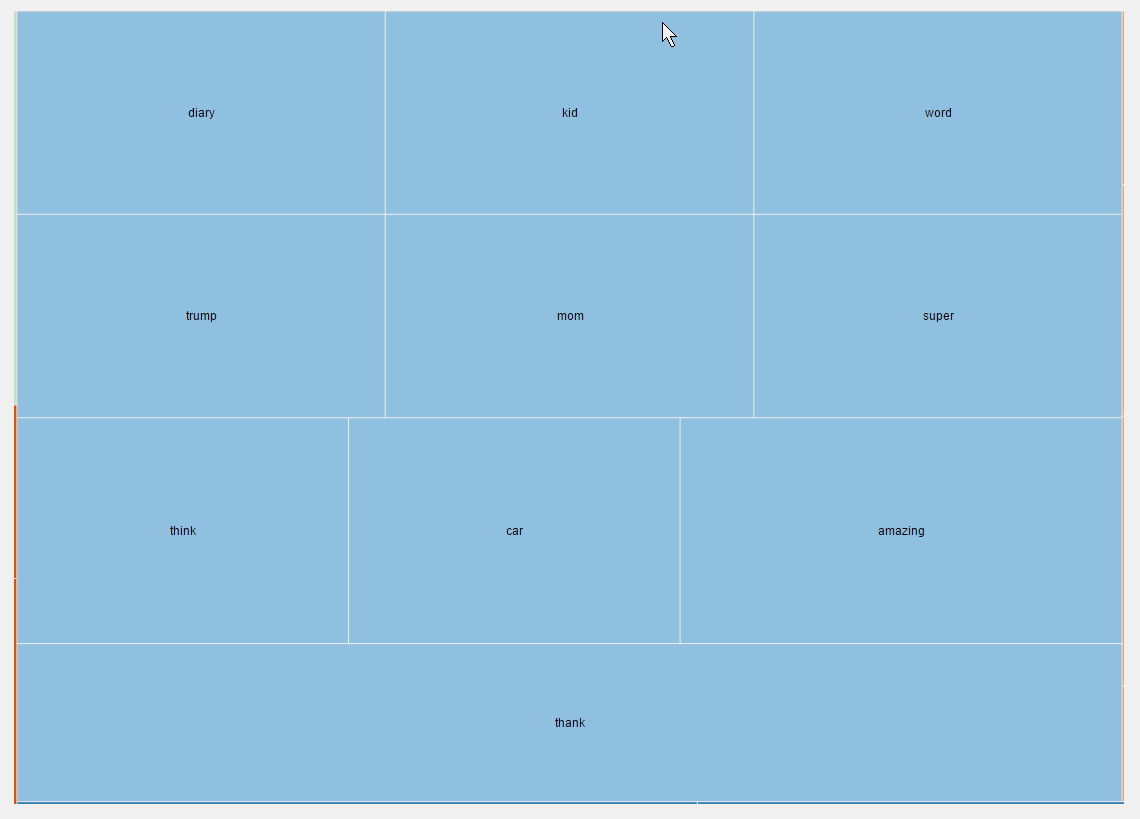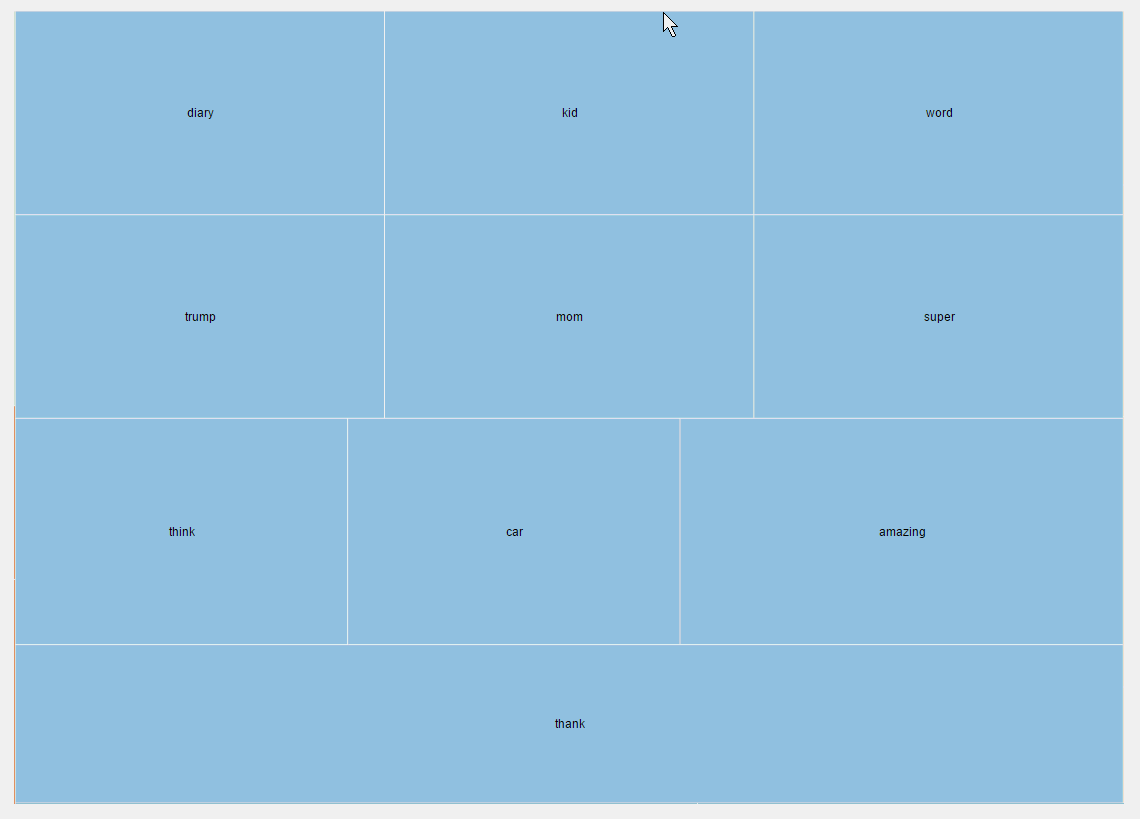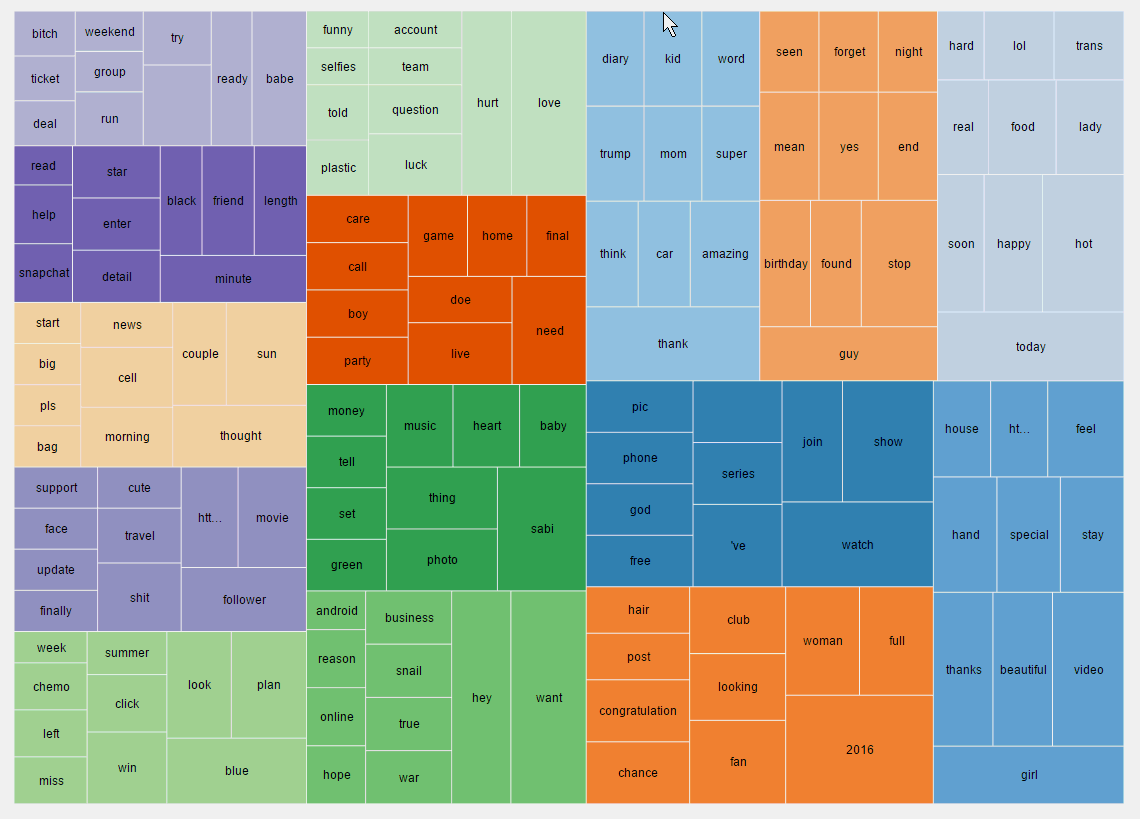
在LDA主题模型中,输出结果有两个矩阵,其中一个是主题-单词矩阵,这也是本小节要探讨的可视化内容。
为了能够很好的表示出主题以及对应的单词,本文提出可以使用矩形树图(TreeMap)、气泡图(Bubble)、以及旭日图(Sunburst)来表示LDA的结果。
矩形树图
矩形树图是由一个个矩形递归组成的。
同一个颜色表示同一主题,而矩形大小表示概率大小。
在图形交互方面,矩形树图支持点击后放大查看。
气泡图
同一个主题同一个圈,同一个圈内的圆大小表示概率的大小。
在图形交互方面,气泡图支持点击后放大查看某一主题下的内容。
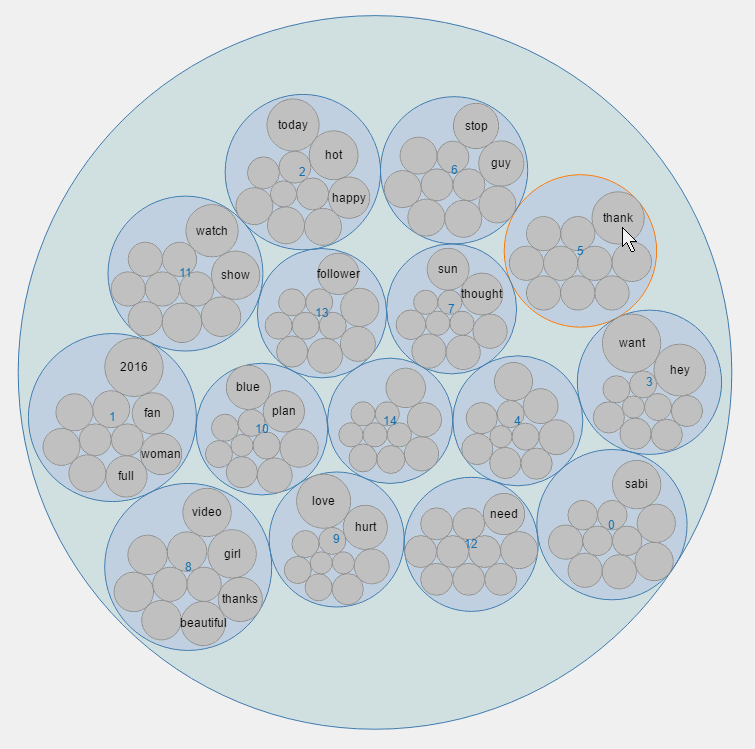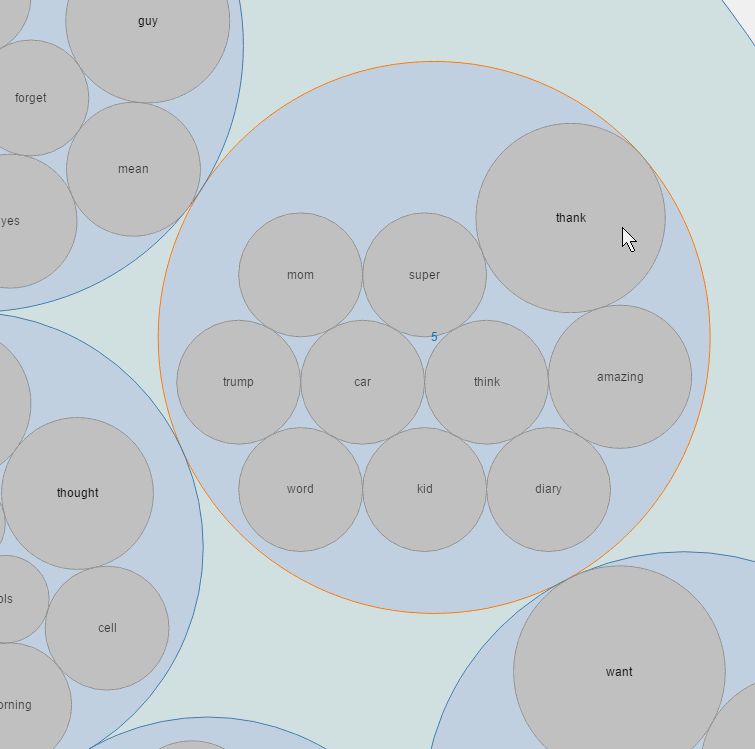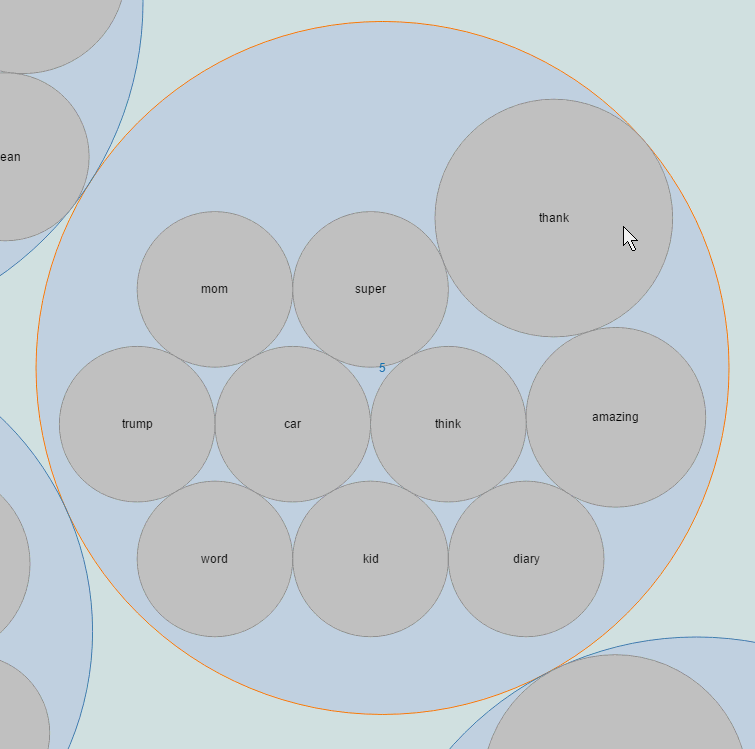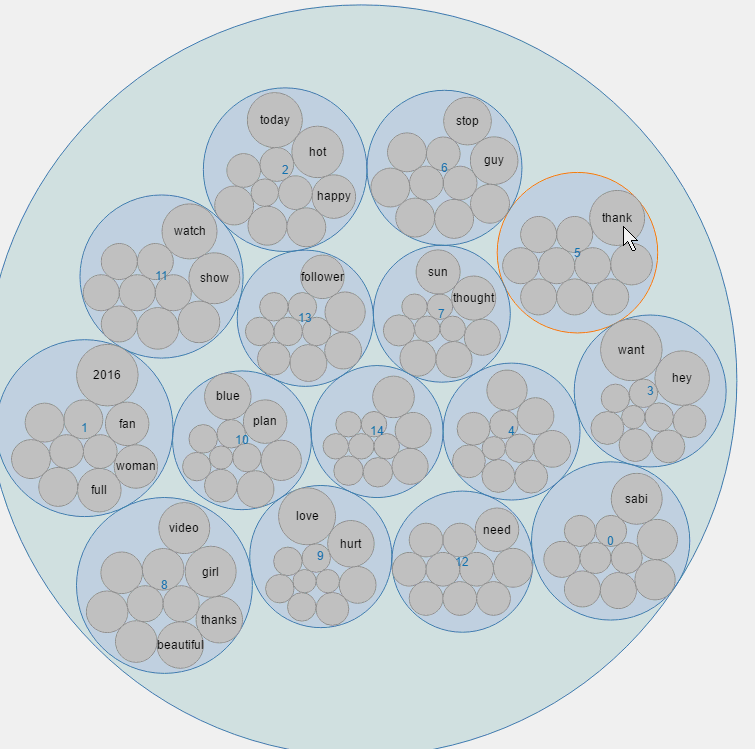
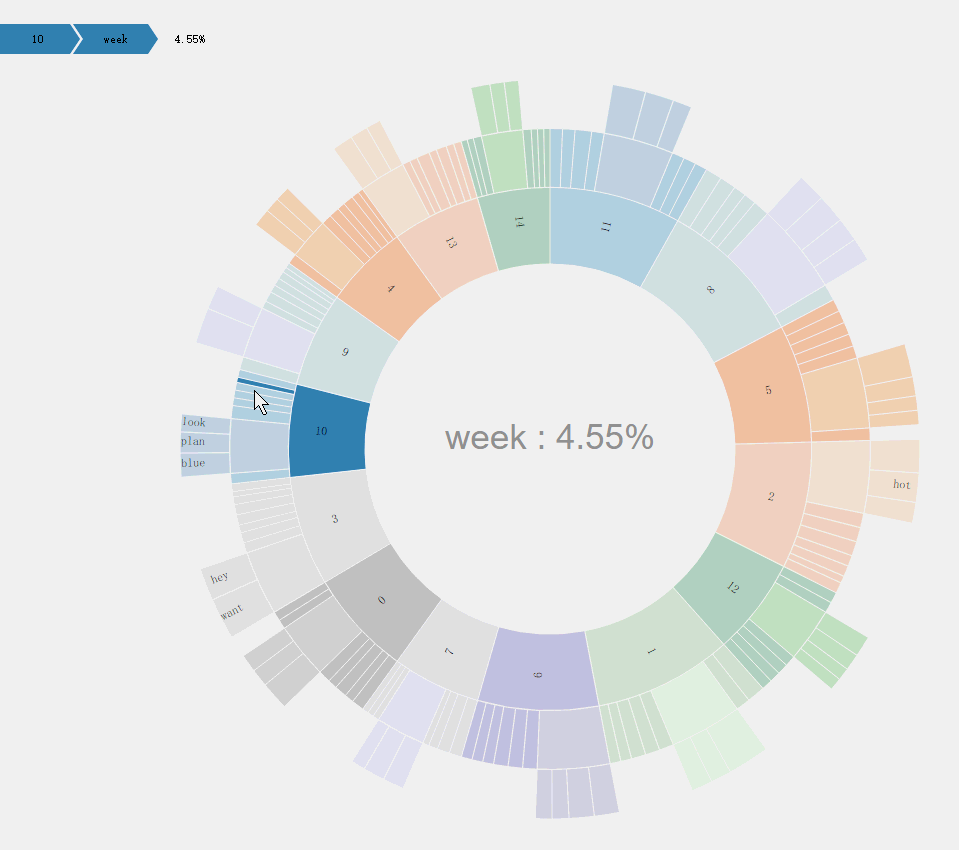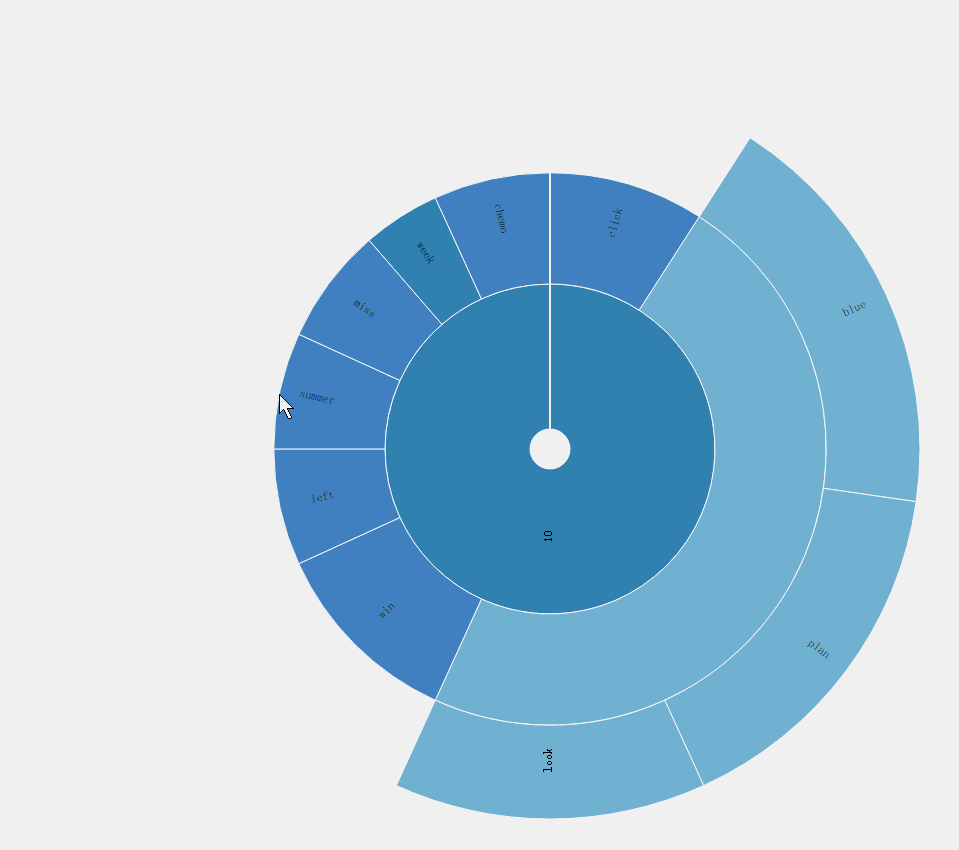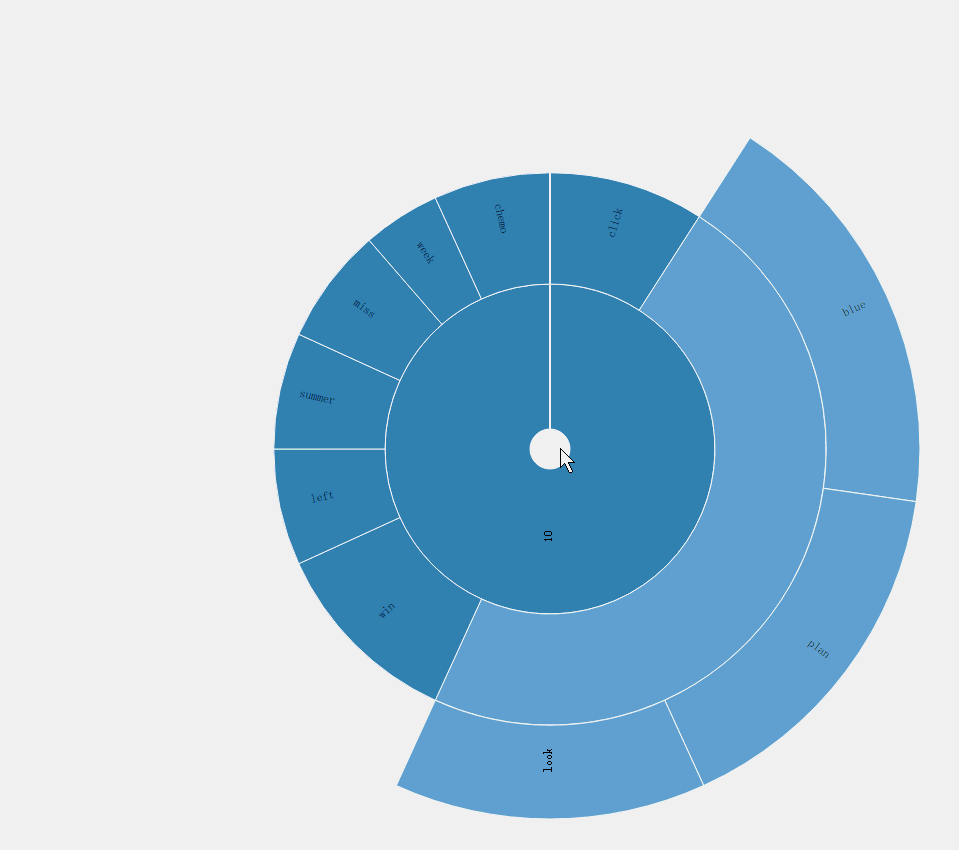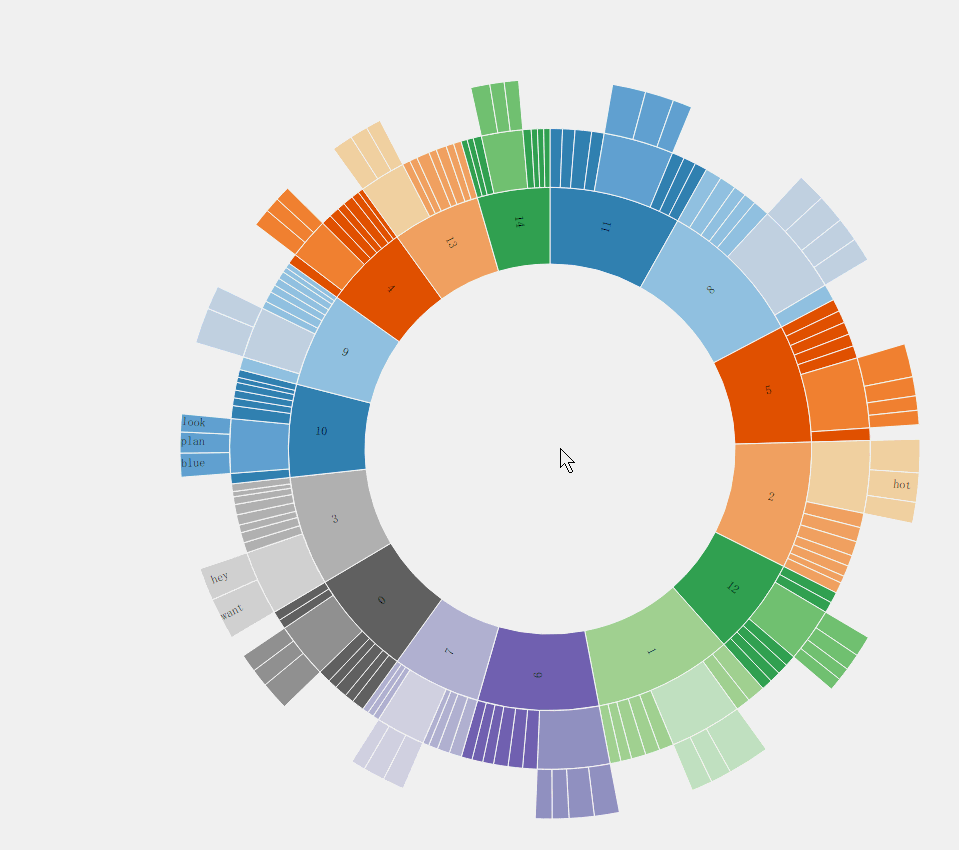
旭日图
旭日图它可以说是饼状图的升级版。在最内圈的数据为每个主题,同时,用不同的颜色加以区分,内圈所占的大小就反映了主题的热度。接着,对于每个主题,向外延伸出对应的主题词,每个主题词占的面积大小就反映了其概率的大小。此外,本文做出了特殊的处理,将主题词中更重要的主题词在加一层显示。
最重要的主题词计算方法为:按主题的概率从大到小排序,然后,从大到小进行遍历,对概率和进行累加,当对某一项i累加后的和大于0.4,则从第一个主题词到第i个主题词为该主题的最重要的主题词。
旭日图的用户交互为,点击某一块区域,则图形变化为某主题下的单词概率分布饼图。
情感分析的可视化
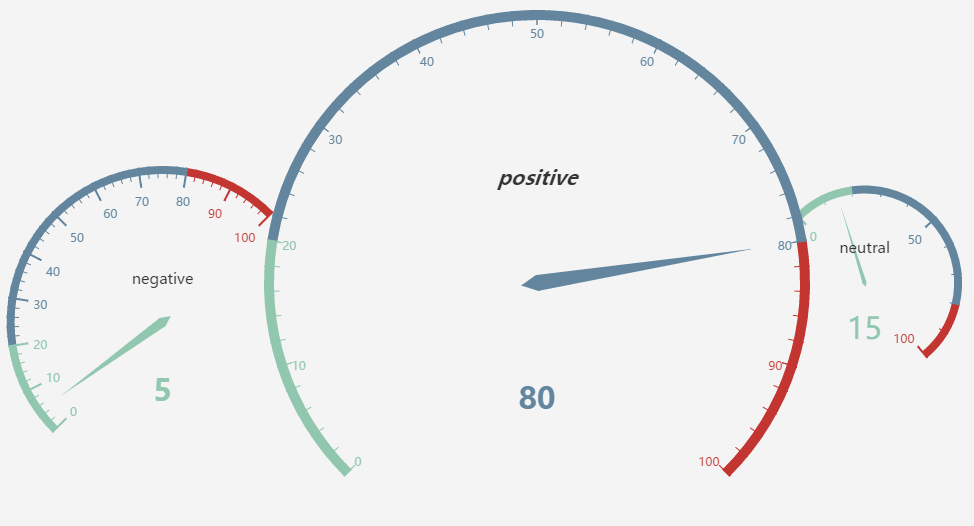
针对于情感分析,我们的任务是对于给定一些推文,判断其实情感类别。在分类结果完成后,我们可以对分类的结果进行统计。可以采用类似于对Hashtag的统计结果进行可视化的方法,如柱状图、饼状图,这里不再赘述。此外,还可以用“仪表盘”的方式来进行可视化。
Twitter数据挖掘平台的设计与实现
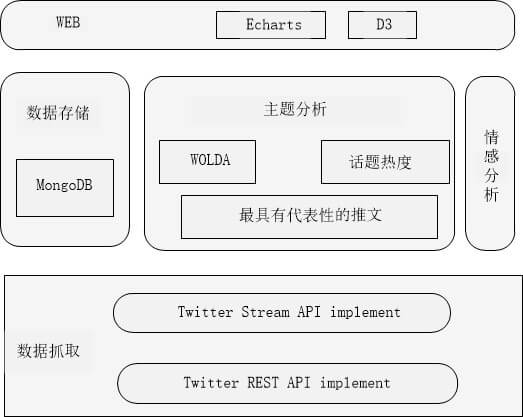
本章基于前面几个章节所讨论的问题与相关的算法,设计并实现了Twitter数据挖掘与可视化系统。这个系统主要包含数据抓取模块、数据存储模块、主题分析模块、情感分析模块、WEB模块一共六大模块。开发系统时使用Git进行版本控制,并且提交到Github这个开源代码网站,方便多个人共同进行开发和维护。
系统的总体框架
本文系统的后端使用了Python的Django框架,前端可视化采用了D3.js和Echarts,除此之外,使用了JQuery + Bootstrap进行用户界面的快速开发。数据存储方面,使用的是MongoDB数据库。
下面是框架图:
数据抓取模块
数据抓取模块的主要功能是根据用户想要追踪的信息,向Twitter发送相应的请求。对于数据挖掘的平台来说,一个健壮的数据挖取模块是十分必要的。这个模块除了应对超过API的限定的速率错误外,各种HTTP的错误也是需要进行处理的。Twitter常见的HTTP错误及应对措施如下:
| 错误代码 | 错误描述 | 应对措施 |
|---|---|---|
| 401 | 无OAuth验证或验证失败 | 提示进行OAuth验证 |
| 404 | URI请求不合法或查询内容不存在 | 返回空 |
| 429 | 超出速率限制 | 等待15分钟继续,或者换另外一个账号继续抓取 |
| 500,502,503,504 | 服务器错误 | 等一段时间继续,每次错误将等待时间延长,超过一定的错误次数报错。 |
更多的Twitter从错误代码详见Twitter开发者平台。
数据存储模块
数据存储的功能主要是对于数据抓取模块所抓取的数据进行存储,方便日后的继续研究;以及对存储内容的读取、查询。主要用到了MongoDB数据库。
MongoDB
MongoDB是由C++语言编写的,一个基于分布式文件存储的开源数据库系统。同时,MongoDB也是一种NoSQL(Not only SQL)数据库。
它可以方便的进行数据分片,采用水平扩展的方式,添加更多的节点,来保证服务器的性能,并且成本相对垂直扩展来说更加低廉,同时,它原生的支持Map-Reduce操作。
文献[46]比较了MongoDB和MySQL的优缺点。文献[47]和文献[48]比较了mongodb和关系型数据库如MySQL,MS-SQL数据库的速度,结论是mongodb具有更快的速度。
关系型数据库与NoSQL数据库 数据大小-查询时间对比图如下[33]
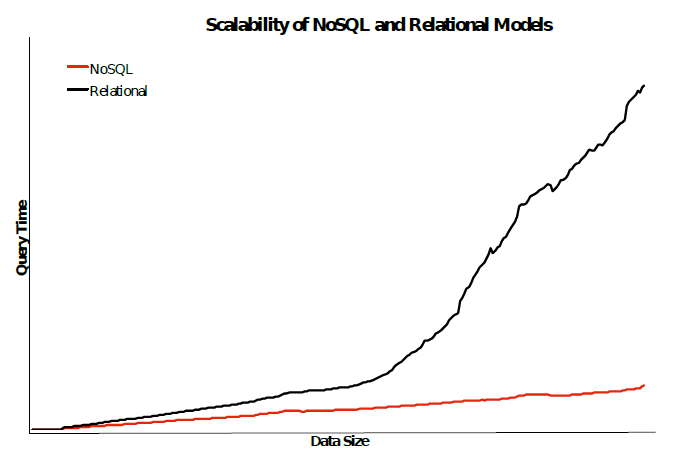
正是由于MongoDB有更好更稳定的性能,且数据格式为JSON和twitter返回的一致。因此本系统选择了MongoDB作为数据库,并采用了索引技术。
数据压缩
MongoDB将数据存储为一个文档,数据结构由键值对(key=>value)组成。MongoDB 文档的存储类型是BSON,它类似于 JSON 对象。字段值可以包含其他文档,数组及文档数组。它不像MySQL之类的关系型数据库,必须先指定好数据表中的列,而可以随意的增加或删除文档中的字段(即关系型数据库中的列),但每一条数据都要保存相应的字段名。
Twitter 返回的原始推文信息是十分庞大的,除了140字符的文字,还有许多其他的字段。若将其展开,其内容将会超过5KB,这大约我们认为的140个字符文字的37倍!并且由于Twitter中有大量的字段经常为空,用MongoDB进行存储时,不管该字段是否为空,都会进行存储,这样一来将占据大量的存储空间,并且其占据的空间与字段长度成正相关的关系。比如说,"in_reply_to_user_id" 一栏往往为空,但是存储中仍会有这个字段。
对此,需要对字段进行删减,只保留一些有用的字段,当该字段为空的时候不存储,且对字段进行重命名操作,减少其长度。
更新后所保留的字段如下表:
| 字段名 | 原字段名 | 类型 |
|---|---|---|
| geo | coordinates | array |
| date | created_at | date |
| like | favorite_count | int |
| id | id_str | string |
| reply_id | in_reply_to_status_id_str | string |
| reply_user_id | in_reply_to_user_id_str | string |
| quoted_id | quoted_status_id_str | string |
| retweet_id | retweeted_status[‘id_str’] | string |
| retweet_count | retweet_count | int |
| text | text | string |
| use_id | user[‘user_id_str’] | string |
| hashtags | entities[‘hashtags’][‘text’] | array |
| urls | entities[‘usrls’][‘expanded_url’] | array |
| user_mentions | entities[‘mentions’][‘id_str’] | array |
一个直观的对比就是1000多万条推文的时候,按Twitter API返回的结果直接进行存储,就有97.906GB的空间。而精简后的只剩下了9.949GB,体积减少了将近90%,但是携带的有用的信息几乎没少,这有利于数据的查询和存储。
主题分析模块
主题的模块主要是对推文数据进行主题的挖掘,这些推文数据可以来自抓取模块中实时获取的Twitter数据,也可以来自数据存储模块中获取历史的数据。通过对数据的实时计算,计算出主题词以及最具有代表性的推文,并按照话题的热度进行排序,返回给前台页面。
对于在线的数据流,本文使用了多线程,一个线程进行调用Stream API请求,一个线程进行WOLDA模型的计算,一个线程负责接收WOLDA的结果。具体的流程如下:
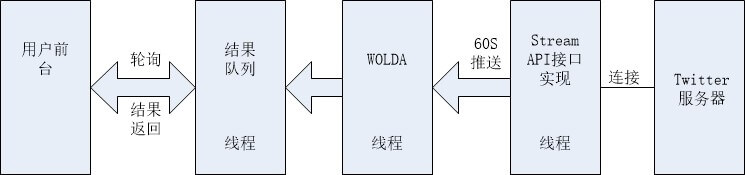
其中,涉及到了线程安全,如从结果队列中取出数据的时候,需要对其进行加锁等。
使用在线数据时,默认对每分钟的数据进行计算。采用一分钟的计算间隔是基于如下几点考虑:(1)若时间过短,那么推文数过少,更新没有太多的意义(2)若设置时间过长,则可能无法第一时间捕捉到紧急的话题等。因此,本文采用一分钟的间隔,这样可以保证话题的实时性又不会有过多无用的计算。
此外,用户可自定义WOLDA算法的相应参数,如时间窗口L,主题数K等。
情感分析模块
情感分析模块调用了抓取模块,将用户待查询的关键字作为参数,然后对Twitter返回的推文进行情感分析。将推文进行情感分析之后,并且返回一些参考的推文在前台展示。
这其中,需要用到之前的情感分析算法,只不过分类器是已经训练好的,只需要对推文进行相应的预测即可。
WEB模块
WEB模块主要作用是用户交互,包括了用户的界面、用户自定义的参数处理、结果的可视化等。
为了改善用户体验,使用了AJAX技术,在获取服务器分析的结果时,添加等待效果。(见为AJAX添加等待效果)
此外,利用了Google Map API在地图上点击来获取地区的经纬度,方便对某地区进行话题追踪。(见使用google map API获取经纬度)
界面展示
总结与展望
主要内容总结
- 提出了WOLDA算法,该算法改进自Hoffman的OLDA算法。WOLDA算法使用动态的词库,能更好的处理流式数据并进行周期性的更新,并且该方式资源占用稳定,不随时间的增大而无限的增大,保证效率和对新话题的敏感程度。同时,提出了最具有代表性推文的计算方法,方便对于主题的理解和分析。
- 结合了基于情感词典的方法和基于机器学习的方法,将情感词典作为分类器的一部分特征,在SemEval2016最新的结果中,取得较为靠前的排名。
- 提出了Twitter进行可视化的方法,包括简单的统计、主题模型结果的可视化、情感分析结果的可视化。
- 基于本文中算法和可视化的方法,设计并实现了Twitter数据挖掘与可视化平台。
工作展望
本文所涉及的相关研究仍有不足,为此,以下列出了主要可以改进的内容:
热点话题方面
- 本文WOLDA仍需要手动的指定主题的个数K,这个K值将影响结果的好坏,K如果设置过大,那么原本属于一个主题的将会被拆分成多个主题;若设置过小,则多个主题可能会被合并为一个。为此,需要合适的方法来动态的设置主题个数。
- WOLDA算法本质上仍是一个LDA模型,无法克服LDA对于Twitter这样的的短文本效果不佳的状况。它不能简单的采用LDA-AT的模型进行改进,因为在短时间内,同一作者的推文往往数量极少,因此可能需要对整个模型本身进行重构。
- 推文中有大量的无意义的内容,可以进一步使用命名实体识别(NER)来进行去除。
情感分析方面
- 进一步的提高对于反语分类的精度。
- 可以采用word2vector来代替ngram来表示词的特征
- 情感分析的对象可以不受限于文本,Twitter的图片等多媒体信息也是可以进行研究的。
数据挖掘系统
- 进一步提高系统的稳定性与用户操作的便利性。
- 随着数据的不断增多,对于数据存储,由于采用MongoDB,可以方便的采用数据分片的方式来解决。相应的算法可以考虑移植到Spark上运行,提高对海量数据的运算能力。
除了以上的几个改进方面外,本论文只探讨了Twitter下的数据挖掘,未来可以转向对新浪微博进行相关的研究。
本文的代码已在Github开源: twitterDataMining

