继vectornet之后,Waymo 行为预测的paper:《TNT: Target-driveN Trajectory Prediction》
Overview
对于自动驾驶的预测任务来说,其他agent具有高度不确定性,通常是一个多模态的结果(multimodal distribution),比如,可能会直行、或者左转。
在过去的工作中,多模态的建模有用conditional variational autoencoders (CVAEs) generative adversarial networks (GANs) 和 single-step policy roll-out 的方法。这些方法虽然效果不错,但是使用隐变量的方法很难进行解释,且时常需要用sample的方式来评估一些任务(如左转的概率有多大?)。并且容易遇到模态坍缩的问题(mode collapse)。
因此,在TNT这篇paper中,将预测任务拆解为三步:
- 给定环境的context,估计每个候选点的可能性,从而选择概率高的候选点,下图分别用钻石和星星表示候选点和选中点
- 根据目标,估计每个选定目标的轨迹(分布)
- 对所有的轨迹进行排名的评分和选择
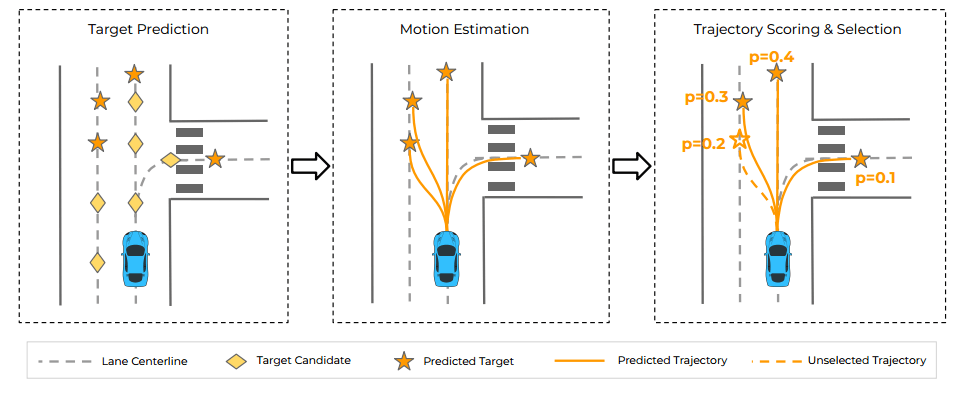
虽然最后训练是end-to-end,但是经过了上面的三个步骤,每个步骤的输出都是可解释,部署时更容易和专家知识结合。
TNT在Argoverse Forecasting dataset 和INTERACTION dataset 取得了最好的效果。行人预测的任务中,在Stanford Drone dataset 和in-house Pedestrian-atIntersection dataset都取得了最好的效果。
建模
公式描述
给定agent历史的状态\(\boldsymbol{s}_p = [s_{-T'+1}, s_{-T'+2}, \cdots, s_0]\),预测的任务是预测其未来的状态\(\boldsymbol{s}_F = [s_{1}, s_{2}, \cdots, s_T]\)。另外,还有相关的环境context历史信息\(\boldsymbol{c}_p = [c_{-T'+1}, c_{-T'+2}, \cdots, c_0]\)。
因此,输入可以写为\(\boldsymbol{x} = (\boldsymbol{s}_p, \boldsymbol{c}_p)\), 最后想要求取的概率分布是\(p(\boldsymbol{s}_F|\boldsymbol{x})\).
前面提到过\(p(\boldsymbol{s}_F|\boldsymbol{x})\)是一个多模态的。未来的不确定性可以分解为两个部分:一个是意图的不确定性(如是要左转还是右转),一个是控制的不确定性(如执行转弯需要的fne-grained motion )。因此这里将它拆解: \[ p\left(\boldsymbol{s}_F | \boldsymbol{x}\right) = \int_{\tau \in \mathcal{T}(c_p)} p(\tau|\boldsymbol{x}) p(\boldsymbol{s}_F | \tau, \boldsymbol{x}) d\tau \] \(\mathcal{T}(c_p)\)这个表示在观察的context历史信息\(\boldsymbol{c}_p\)下,隐含的target空间。
因此,\(p(\tau | \boldsymbol{x})\)就代表了到target的概率,能够表示出意图的不确定性,实践中可以看成是一个分类的任务;而当target 已经确定了之后,control的不确定性在之后的实验中证明可以用简单的单模态分布来表达。
总的来说,TNT的流程如下图:
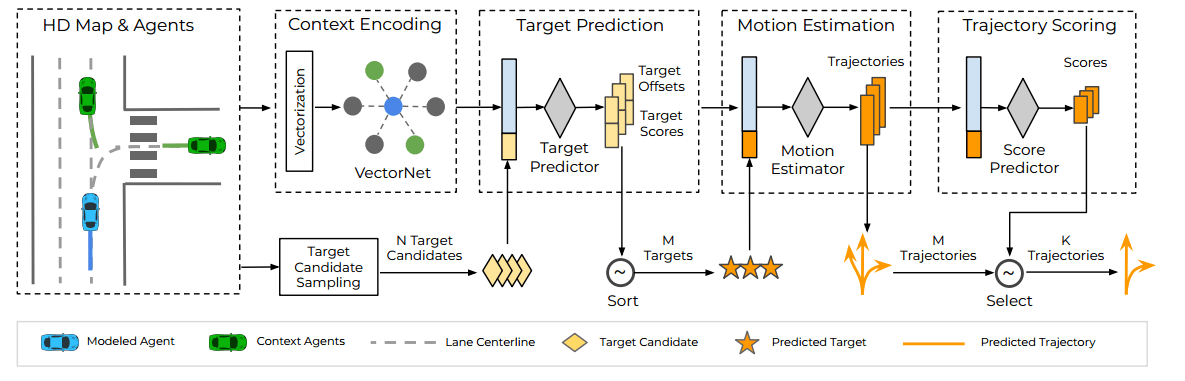
环境encoding
当HDMap是可用的时候,采用了vectorNet来encode环境的上下文; 当HDMap不可用的时候,采用语义地图cnn来encode环境
步骤1. target prediction
实践中,将会有N个候选的target,每个target有中心位置和偏离的offset : \(\mathcal{T} = \{\tau^n\} = \{(x^n, y^n) + (\Delta x^n, \Delta y^n)\}_{n=1}^N\)
target的分布可以用下面离散化的形式表示: \[ p(\tau^n | \boldsymbol{x}) = \pi(\tau^n | \boldsymbol{x}) \cdot \mathcal{N}(\Delta x^n | v_x^n(\boldsymbol{x})) \cdot\mathcal{N}(\Delta y^n | v_y^n(\boldsymbol{x})) \]
其中,\(\pi(\tau^n|\boldsymbol{x}) = \exp f(\tau^n, \boldsymbol{x}) / \sum_{\tau'} f(\tau', \boldsymbol{x})\)是选中第n个target的概率,\(\mathcal{N}(\cdot|v(\cdot))\)是normal的distribution(假设方差为1)。
\(f(\cdot)\)和\(v(\cdot)\)实现中采用2层的MLP,输入为\((x^k, y^k)\)和环境context特征\(\boldsymbol{x}\),用来预测target的概率和最可能的offset。训练的loss function定义如下: \[ \mathcal{L}_{s1} = \mathcal{L}_{cls}(\pi, u) + \mathcal{L}_{offset}(v_x, v_y, \Delta x^u, \Delta y^u) \] \(\mathcal{L}_{cls}\)采用cross entropy作为Loss,\(\mathcal{L}_{offset}\)采用hubder作为loss, u是最接近ground truth location的target,\(\Delta x^u\)和\(\Delta y^u\)则是偏离ground truth的距离。
值得一提的是,对于机动车和行人采用不一样的target表示,如下图所示:
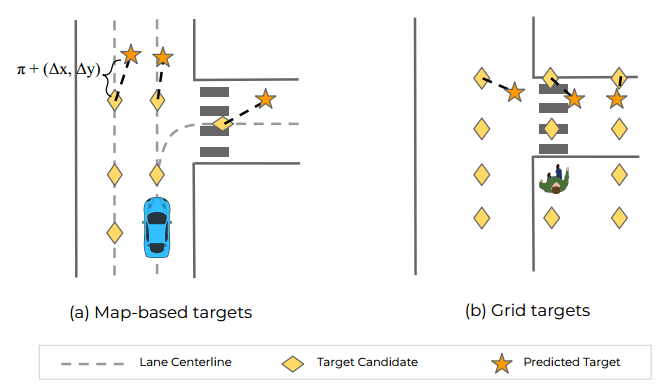
- 对于机动车:对lane的centerlines进行均匀采样作为候选的target(标记为黄色菱形)
- 对于行人,在agent的周围产生虚拟的grid,并用grid point作为target的候选
与直接regression相比,采用离散的target可以有效的防止mode averaging的问题。
在实践中,生成了较大的candidate(如N = 1000),最后选了较少的点作为输出(如M = 50)。
步骤2. Target-conditioned motion estimation
在第二步中,将给定目标的轨迹概率定义为:\(p(\boldsymbol{s}_F | \tau, \boldsymbol{x}) = \prod_{t=1}^T p(s_t | \tau, \boldsymbol{x})\).
这里有两个假设:
- future time是条件独立的,这样使得计算更加高效
- 给定target后轨迹们的分布是unimodal的
具体的实现上,采用了2layer的MLP,将上下文特征\(\boldsymbol{x}\)和target的location \(\tau\)作为输入,对每个target输出最可能的未来轨迹\([\hat{s}_1, \cdots, \hat{s}_T]\).
损失函数如下: \[ \mathcal{L}_{s2} = \sum_{t=1}^T \mathcal{L}_{reg}(\hat{s}_t, \hat{s}_t) \] \(\mathcal{L}_{reg}\)同样是Huber loss
步骤3. Trajectory scoring and selection
最后一个步骤中,是从生成的轨迹中选出最可能的轨迹。
注意,可能某个target有很高的likelihood, 但是结合轨迹来说可能最后的概率就没有那么高了。
论文采用下面的公式来最大化概率: \[ \phi(\boldsymbol{s}_F | \boldsymbol{x}) = \frac{\exp(g(\boldsymbol{s}_F, \boldsymbol{x}))}{\sum_{m=1}^M\exp(g(\boldsymbol{s}_F^m, \boldsymbol{x}))} \] 这里\(g(\cdot)\)也是2层的MLP。损失函数采用的是预测的分数和ground truth score之间的cross entropy: \[ \mathcal{L}_{s3} = \mathcal{L}_{CE}(\phi(\boldsymbol{s}_F|\boldsymbol{x}), \psi (\boldsymbol{s}_F)) \] 每条预测轨迹的ground truth score定义为到ground truth trajectory的距离 : \[ \psi (\boldsymbol{s}_F) = \frac{\exp\left(-D\left(\boldsymbol{s, s_{GT}}\right) / \alpha\right)}{\sum_{s'}\exp\left(-D\left(\boldsymbol{s', s_{GT}}\right) / \alpha\right)} \] \(D(\boldsymbol{s^i, s^j})= \max(||s_1^i - s_1^j||_2^2, \cdots, ||s_t^i - s_t^j||_2^2)\),而\(\alpha\)为temperature,有些蒸馏的味道。
为了从M条轨迹中选出最终K条轨迹,还借鉴了目标检测中的非极大值抑制( non-maximum suppression)的方法,提出了一个去除比较近似的重复轨迹:首先根据所有轨迹的概率进行排序,然后贪心的进行选择,如果一条轨迹距离已经选中的轨迹较远,则选择它,否则就放弃它。这里的距离也和scoring process的方法一样。
Training and inference details
最终,模型的loss就是之前的3个loss加起来: \[ \mathcal{L} = \lambda_1\mathcal{L}_{s1} + \lambda_2\mathcal{L}_{s2}+\lambda_3\mathcal{L}_{s3} \] 在推理的阶段,TNT的步骤如下:
- encode context
- sample N个候选的target,并用\(\pi(\tau|\boldsymbol{x})\)选中top的M个。
- 对M个target进行轨迹的估计\(p(\boldsymbol{s}_F | \tau, \boldsymbol{x})\)
- 从M条轨迹中用\(\phi(\boldsymbol{s}_F |\tau, \boldsymbol{x})\)进行打分,并选中top K
实践中, λ1 = 0.1; λ2 = 1.0; λ3 = 0.1.
实验
数据集
- Argoverse forecasting dataset [9] provides trajectory histories, context agents and lane centerline for future trajectory prediction. There are 333K 5-second long sequences in the dataset. The trajectories are sampled at 10Hz, with (0, 2] seconds for observation and (2, 5] seconds for future prediction.
- INTERACTION dataset [10] focuses on vehicle behavior prediction in highly interactive driving scenarios. It provides 4 different categories of interactive driving scenarios: roundabout (10479 vehicles), un-signalized intersection (14867 vehicles), signalized intersection (10933 vehicles), merging and lane changing (3775 vehicles).
- In-house Pedestrian-at-Intersection dataset (PAID) is an in-house pedestrian dataset collected around crosswalks and intersections. There are around 77K unique pedestrians for training and 12k unique pedestrians for test. The trajectories are sampled at 10Hz, 1-sec history trajectory is used to predict 3-sec future. Map features include crosswalks, lane boundaries and stop/yield signs.
- Stanford Drone dataset (SDD) [11] is a video dataset with top-down recordings of college campus scenes, collected by drones. The RGB video frames provide context similar to road maps in other datasets. We follow practice of other literature [2, 16, 37], focusing on pedestrian trajectories only: frames are sampled at 2.5 Hz, 2 seconds of history (5 frames) are used as model input, and 4.8 seconds (12 frames) are the future to be predicted.
实现的一些细节
除了Stanford Drone dataset没有map data使用了ResNet50 ConvNet作为环境的encoding ,其余的都用vectorNet。
对于Vectornet来说,Argoverse dataset按照lane centerlines来sample points, INTERACTION dataset用lane boundaries来sample points,它们都是一米一个点。
在行人预测中,以agent周围创建2D的grid(e.g. \(10m*10m\)),每个cell的中心(e.g. \(1m*1m\))作为target candidate。
模型方面:TNT三个阶段都采用2层的MLP,hidden unit都是64。 $(_F) $ 中的temperature α 设置为 0.01.
学习Loss方面,λ1 = 0.1; λ2 = 1.0; λ3 = 0.1.
Ablation Study
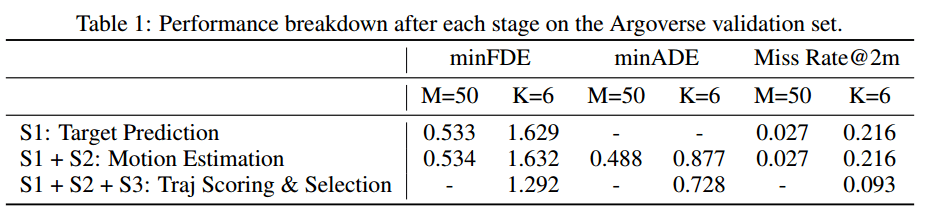
首先对三个阶段进行对比,结果如上表。 s1在M = 50的时候,minFDE和 Miss Rate都挺好;s2和s1基本差不多,说明可以通过target来generate轨迹。S3在k=6的时候相比M=50没有太多loss的损失
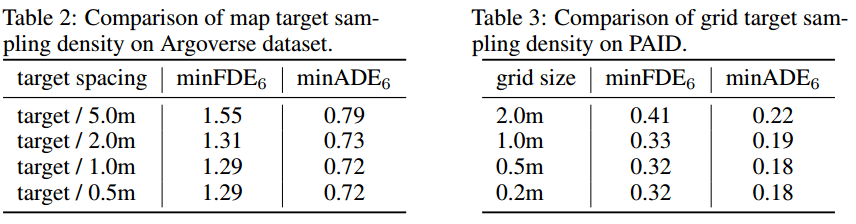
表2和表3说明了target candidate sampling的密度的影响。发现越密效果越好

表4对比了有无target offset regression,发现有offset regression之后,效果有一定的提高。
表5对比了在s2阶段Huber regressor和CVAE regressor。发现他们在只有一条tarj的时候效果差不多,但是当CVAE的条数增加到10的时候,仅对minADE指标有改善。这验证了在s2阶段 agent motion采用unimodal的假设。
Comparison with state-of-the-art
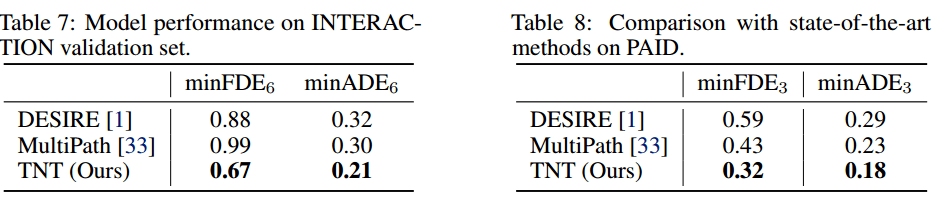
Table7说明了TNT在机动车上的下偶偶最好
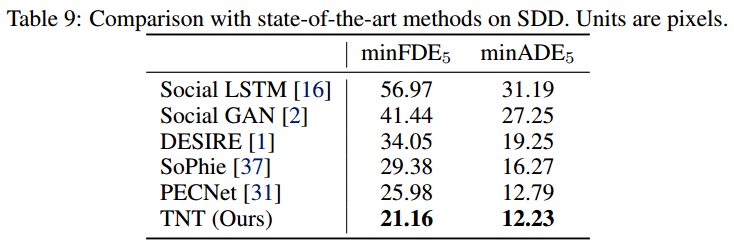
Table8和9说明了在PAID数据集和SDD数据集的行人预测上效果最好。
参考文献
- Zhao H, Gao J, Lan T, et al. Tnt: Target-driven trajectory prediction[J]. arXiv preprint arXiv:2008.08294, 2020.

