本文将详细的介绍单纯形算法,包括但不限于
- LP问题
- 单纯形算法原理
- 无界、无解、循环等情况
- python代码实现
线性规划问题
首先引入如下的问题:
假设食物的各种营养成分、价格如下表:| Food | Energy(能量) | Protein(蛋白质) | Calcium(钙) | Price |
|---|---|---|---|---|
| Oatmeal(燕麦) | 110 | 4 | 2 | 3 |
| Whole milk(全奶) | 160 | 8 | 285 | 9 |
| Cherry pie(草莓派) | 420 | 4 | 22 | 20 |
| Pork with beans(猪肉) | 260 | 14 | 80 | 19 |
要求我们买的食物中,至少要有2000的能量,55的蛋白质,800的钙,怎样买最省钱?
设买燕麦、全奶、草莓派、猪肉为\(x_1,x_2,x_3,x_4~\)
于是我们可以写出如下的不等式组
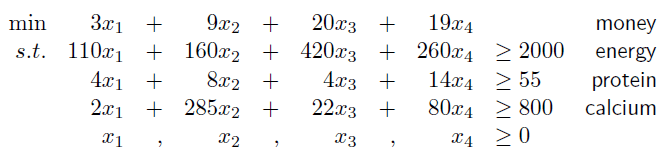
其实这些不等式组就是线性规划方程(Linear programming formulation)。
简单的说,线性规划就是在给定限制的情况下,求解目标。
可行域
来看一个算法导论中的例子,考虑如下的线性规划: \[ \begin{alignat}{2} \max\quad &x_1 + x_2& \\ \mbox{s.t.}\quad &4x_1 - x_2 &\leq&{8} \\ &2x_1 + x_2 & \leq&{10}\\ &5x_1 - 2x_2 & \geq&{-2}\\ &x_1, \quad x_2 &\geq&{0} \\ \end{alignat} \] 我们可以画出下面的图:
看图a,灰色的区域就是这几个约束条件要求\(x_1,x_2\)所在的区域,而我们最后的解\(x_1,x_2\)也要在这里面。我们把这个区域称为可行域(feasible region)
图b可以直观的看出,最优解为8, 而 \(x_1=2,x_2=6\)
线性规划标准形式
线性规划的标准形式如下:
\[ \begin{alignat}{2} \min\quad &&&&c^Tx& \\ \mbox{s.t.}\quad & &A&x &\leq{b}\\ & &&x & \geq{0} &\\ \end{alignat} \]
就是
- 求的是min(算法导论的是max,本文为min)
- 所有的约束为<=的形式
- 所有的变量均 >=0
如何变为标准形式?
- 原来是max, 直接*-1求min
- 若原来约束为=,转为 >= 和<=
- 约束原来为 >= 同样的*-1,就改变了<=
- 若有变量 \(x_i < 0\) ,那么用 \(x^{'} - x^{''}\)来替代,其中 \(x^{'}>=0, x^{''}>=0\)
线性规划松弛形式
松弛形式为:
\[ \begin{alignat}{2} \min\quad &&&&c^Tx& \\ \mbox{s.t.}\quad & &A&x &={b}\\ & &&x & \geq{0} &\\ \end{alignat} \]
就是通过引入变量把原来的 <= ,变为=的松弛形式.
如:
\[ \begin{alignat}{2} &x_1 + x_2 &\leq{2} \\ &x_1 + x_2 & \geq{1}\\ &x_1, \quad x_2 &\geq{0} &\\ \end{alignat} \] 写为松弛形式就是: \[ \begin{alignat}{2} &x_1 + x_2 + x_3&={2} \\ &x_1 + x_2 + x_4& ={1}\\ &x_1,x_2,x_3,x_4 &\ge{0} &\\ \end{alignat} \]
<= vs <
有砸场子的同学会问(╯‵□′)╯︵┻━┻,为什么我们的线性规划的形式都是可以 <= 或者 >=的形式的?把等号去掉可以么?
就是不可以( ̄ε(# ̄)
举个例子
\[ \begin{alignat}{2} \max\quad &x& \\ \mbox{s.t.}\quad & x \leq{1}&\\ \end{alignat} \]
\[ \begin{alignat}{2} \max\quad &x& \\ \mbox{s.t.}\quad & x \lt{1}&\\ \end{alignat} \]
显然第二个是无解的。
单纯形算法的思想与例子
如何求解线性规划问题呢?
有一些工具如GLPK,Gurobi 等,不在本文的介绍范围内。
本文要介绍的是单纯形算法,它是求解线性规划的经典方法,虽然它的执行时间在最坏的情况下是非多项式的(指数时间复杂度),但是,在绝大部分情况下或者说实际运行过程中却是多项式时间。
它主要就三个步骤
- 找到一个初始的基本可行解
- 不断的进行旋转(pivot)操作
- 重复2直到结果不能改进为止
以下面的线性规划为例:
\[ \begin{array}{rrrrrr} \min & -x_1 &-&14x_2 &-&6x_3\\ s.t. &x_1& +&x_2& +&x_3 &\le &\quad4\\ &x_1& && & &\le &\quad2\\ && && & x_3&\le &\quad3\\ && &3x_2& +&x3 &\le &\quad6\\ &x_1& ,&x_2&,&x3 &\ge &\quad0\\ \end{array} \]
将其写为松弛的形式:
\[ \begin{alignat}{2} \min\quad &-x_1 -14x_2 - 6x_3& \\ \mbox{s.t.}\quad &x_1 + x_2 +x_3 + x_4 \quad \quad \quad \quad \quad \quad \quad &=& \quad4&\\ &x_1 \quad \quad \quad \quad \quad \quad \quad+x_5 \quad \quad\quad \quad\quad&=&\quad2&\\ & \quad\quad \quad \quad\quad x_3 + \quad \quad \quad \quad + x_6&=&\quad3&\\ & \quad \quad 3x_2 + x_3\quad\quad \quad \quad\quad \quad \quad +x_7&=&\quad6&\\ &x_1, \quad x_2 ,\quad x_3, \quad x_4, \quad x_5 ,\quad x_6, \quad x_7\quad &\quad\geq{0} &\\ \end{alignat} \]
其实,就是等价于(仍然要求 \(x_1,x_2,x_3,x_4,x_5,x_6,x_7 \ge0\)):
\[ \begin{alignat}{4} &z = \quad-x_1 -14x_2 - 6x_3& \\ & x_4 = \quad4-x_1 - x_2 -x_3 &\\ &x_5 =\quad2 - x_1&\\ &x_6=\quad3 - x_3&\\ & x_7=\quad6 - 3x_2 - x_3&\\ \end{alignat} \]
在上述的等式的左边称为基本变量,而右边称为非基本变量。
现在来考虑基本解就是把等式右边的所有非基本变量设为0,然后计算左边基本变量的值。
这里,容易得到基本解为: \((x_1,x_2,x_3,x_4,x_5,x_6,x_7) = (0,0,0,4,2,3,6)\),而目标值z = 0,其实就是把基本变量\(x_i\)设置为\(b_i\)。
一般而言,基本解是可行的,我们称其为基本可行解。初始的基本解不可行的情况见后面的讨论,这里假设初始的基本解就是基本可行解,因此三个步骤中第一步完成了。
现在开始,来讨论上面的第二个步骤,就是旋转的操作。
我们每次选择一个在目标函数中的系数为负的非基本变量\(x_e\),然后尽可能的增加\(x_e\)而不违反约束,并将\(x_e\)用基本变量\(x_l\)表示, 然后把\(x_e\)变为基本变量,\(x_l\)变为非基本变量。
这里,假设我们选择增加\(x_1\),那么在上述的等式(不包括目标函数z那行)中,第1个等式限制了\(x_1 \le 4\)(因为\(x_4 \ge 0\)),第2个等式有最严格的限制,它限制了\(x_1 \le 2\),因此我们最多只能将\(x_1\)增加到2,根据上面的第二个等式,我们有:\(x_1 = 2- x_5\),带入上面的等式就实现了\(x_e\)和\(x_l\)的替换: \[ \begin{alignat}{4} &z = \quad-2 -14x_2 - 6x_3 + x_5& \\ & x_4 = \quad2 - x_2 -x_3 +x_5&\\ &x_1 =\quad2 - x_5&\\ &x_6=\quad3 - x_3&\\ & x_7=\quad6 - 3x_2 - x_3&\\ \end{alignat} \] 这样其实就是一个转动(pivot)的过程,一次转动选取一个非基本变量(也叫替入变量)\(x_e\)和一个基本变量(也叫替出变量) \(x_l\) ,然后替换二者的角色。执行一次转动的过程与之前所描述的线性规划是等价的。
同样的,将非基本变量设为0,于是得到:\((x_1,x_2,x_3,x_4,x_5,x_6,x_7) = (2,0,0,2,0,3,6)\), Z = -2,说明我们的目标减少到了-2
接下来是单纯形算法的第三步,就是不断的进行转动,直到无法进行改进为止,继续看看刚才的例子:
我们接着再执行一次转动,这次我们可以选择增大\(x_2\)或者\(x_3\),而不能选择\(x_5\),因为增大\(x_5\)之后,z也增大,而我们要求的是最小化z。假设选择了\(x_2\),那么第1个等式限制了\(x_2 <=2\) , 第4个等式限制了\(x_2<= 2\),假设我们选择\(x_4\)替出变量,于是有: \(x_2 = 2-x_3-x_4+x_5\) ,带入得: \[ \begin{alignat}{4} &z = \quad-30 + 8x_3 + 14x_4 -13x_5& \\ & x_2 = \quad2 -x_3 -x_4 +x_5&\\ &x_1 =\quad2 - x_5&\\ &x_6=\quad3 - x_3&\\ & x_7=\quad2x_3 + 3x_4 - 3x_5&\\ \end{alignat} \] 此时,我们的基本解变为\((x_1,x_2,x_3,x_4,x_5,x_6,x_7) = (2,2,0,0,0,3,0)\), Z = -30
我们可以继续的选择增大\(x_5\),第4个等式具有最严格的限制(\(0 - 3x_5 >=0\)),我们有\(x_5=\frac{2}{3}x_3 + x_4 - \frac{1}{3}x_7\)
带入得:
\[ \begin{alignat}{4} &z = \quad-30 - \frac{2}{3}x_3 + x_4 +\frac{13}{3}x_7& \\ & x_2 = \quad2 - \frac{1}{3}x_3 -\frac{1}{3}x_7&\\ &x_1 =\quad2 - \frac{2}{3}x_3 - x_4 + \frac{1}{3}x_7&\\ &x_6=\quad3 - x_3&\\ & x_5=\quad\frac{2}{3}x_3 + x_4 - \frac{1}{3}x_7&\\ \end{alignat} \]
此时,我们的基本解变为\((x_1,x_2,x_3,x_4,x_5,x_6,x_7) = (2,2,0,0,0,3,0)\), Z = -30,这时候并没有增加,但是下一步,我们可以选择增加 \(x_3\)。第2个和第3个有最严格的限制,我们选第2个的话,得:\(x_3=3 - \frac{3}{2}x_1 - \frac{3}{2}x_4 + \frac{1}{2}x_7\),然后老样子,继续带入:
\[ \begin{alignat}{4} &z = \quad-32 + x_1 + 2x_4 + 4x_7& \\ & x_2 = \quad1 + \frac{1}{2}x_1 +\frac{1}{2}x_4 - \frac{1}{2}x_7&\\ &x_3= \quad3 - \frac{3}{2}x_1 - \frac{3}{2}x_4 + \frac{1}{2}x_7&\\ &x_6=\quad \frac{3}{2}x_1 + \frac{3}{2}x_4 - \frac{1}{2}x_7&\\ & x_5=\quad 2 - x_1&\\ \end{alignat} \]
现在,已经没有可以继续增大的值了,停止转动,z=-32就是我们的解,而此时,基本解为:\((x_1,x_2,x_3,x_4,x_5,x_6,x_7) = (0,1,3,0,2,0,0)\),看看最开始的目标函数:\(z = -x_1 - 14x_2 - 6x_3\),我们将\(x_2=1,x_3=3\)带入得,z=-32,说明我们经过一系列的旋转,最后得到了目标值。
退化(Degeneracy)
在旋转的过程中,可能会存在保持目标值不变的情况,这种现象称为退化。比如上面的例子中,两次等于-30.
可以说退化可能会导致循环(cycling)的情况,这是使得单纯形算法不会终止的唯一原因。还好上面的例子中,我们没有产生循环的情况,再次旋转,目标值继续降低。
《算法导论》是这样介绍退化产生循环的:
Degeneracy can prevent the simplex algorithm from terminating, because it can lead to a phenomenon known as cycling: the slack forms at two different iterations of SIMPLEX are identical. Because of degeneracy, SIMPLEX could choose a sequence of pivot operations that leave the objective value unchanged but repeat a slack form within the sequence. Since SIMPLEX is a deterministic algorithm, if it cycles, then it will cycle through the same series of slack forms forever, never terminating.
如何避免退化?一个方法就是使用Bland规则:
在选择替入变量和替出变量的时候,我们总是选择满足条件的下标最小值。
- 替入变量\(x_e\):目标条件中,系数为负数的第一个作为替入变量
- 替出变量\(x_l\):对所有的约束条件中,选择对\(x_e\)约束最紧的第一个
在上面的例子中,我也是这么做的。^ ^
另一个方法是加入随机扰动。
无界(unbounded)的情况
有的线性规划问题是无界的,举个栗子

对于下面的线性规划 \[ \begin{alignat}{2} \min\quad &-x_1 - x_2& \\ \mbox{s.t.}\quad &x_1 - x_2 &\leq{1} \\ -&x_1 + x_2 & \leq{1}\\ &x_1, \quad x_2 &\geq{0} &\\ \end{alignat} \] 画出区域为:
显然可以不断的增大。让我们来看看单纯形算法是如何应对的:
上述的写成松弛形式为: \[ \begin{alignat}{2} \min\quad &-x_1 - x_2& \\ \mbox{s.t.}\quad &x_1 - x_2 + &x_3 &&={1} \\ -&x_1 + x_2 &&+x_4& ={1}\\ &x_1, x_2,x_3, x_4 \geq{0} &\\ \end{alignat} \] 也就是, \[ \begin{alignat}{2} &z &=&-x_1 - x_2&\\ & x_3 &=& 1 - x_1 + x_2& \\ &x_4 &=&1 + x_1 - x_2 & \\ \end{alignat} \] 选择x_1 为替入变量,x_3为替出变量,有: \[ \begin{alignat}{2} &z &=&-1 - 2x_2 + x_3&\\ & x_1 &=& 1 + x_2 - x_3& \\ &x_4 &=&2 - x_3 & \\ \end{alignat} \] 这时候我们只能选择\(x_2\) 为替入变量,才能使得目标值变小,但是我们发现,对于\(x_2\)没有任何的约束,也就是说,\(x_2\)可以无限大,所以这是没有边界的情况。
这个情况是我们有一个替入变量,但是找不到一个替出变量导致的,这时候就是无界的情况了,写算法的时候注意判断一下即可。
单纯形算法的具体实现
说了那么多,代码怎么写呢?
看一下最开始的线性规划的问题(已经是松弛形式): \[ \begin{alignat}{2} \min\quad &-x_1 -14x_2 - 6x_3& \\ \mbox{s.t.}\quad &x_1 + x_2 +x_3 + x_4 \quad \quad \quad \quad \quad \quad \quad &=& \quad4&\\ &x_1 \quad \quad \quad \quad \quad \quad \quad+x_5 \quad \quad\quad \quad\quad&=&\quad2&\\ & \quad\quad \quad \quad\quad x_3 + \quad \quad \quad \quad + x_6&=&\quad3&\\ & \quad \quad 3x_2 + x_3\quad\quad \quad \quad\quad \quad \quad +x_7&=&\quad6&\\ &x_1, \quad x_2 ,\quad x_3, \quad x_4, \quad x_5 ,\quad x_6, \quad x_7\quad &\quad\geq{0} &\\ \end{alignat} \] 我们可以得到下面的矩阵:
\[ \begin{equation} %开始数学环境 C = \left( %左括号 \begin{array}{c} -1 & -14 & -6& 0 &0 &0 &0\\ %第一行元素 \end{array} \right) %右括号 \\ \quad \\ B =\left( \begin{array}{c} 4\\ 2\\ 3\\ 6\\ \end{array} \right) \quad A =\left( %左括号 \begin{array}{c} %c为居中放置 1 & 1 & 1& 1 &0 &0 &0\\ %第一行元素 1 & 0 & 0& 0 &1 &0 &0\\ %第二行元素 0 & 0 & 1& 0 &0 &1 &0\\ %第三行元素 0 & 3 & 1& 0 &0 &0 &1\\ %第四行元素 \end{array} \right) %右括号 \end{equation} \]
- 矩阵A:就是约束条件的系数(等号左边的系数)
- 矩阵B:就是约束条件的值(等号右边)
- 矩阵C:目标函数的系数值
我们将其拼接起来: \[ \begin{equation} %开始数学环境 S_1 = \left( \begin{array}{r} 0& -1 & -14 & -6& 0 &0 &0 &0\\ 4& 1 & 1 & 1& 1 &0 &0 &0\\ 2&1 & 0 & 0& 0 &1 &0 &0\\ 3&0 & 0 & 1& 0 &0 &1 &0\\ 6&0 & 3 & 1& 0 &0 &0 &1\\ \end{array} \right) \end{equation} \]
左下角为B,右上角为C,右下角为A,那么左上角呢?我们放的是-z,初始时-z = 0!
将上面那个矩阵和写成 基本变量 = 非基本变量的形式对比: \[ \begin{alignat}{4} &z = \quad-x_1 -14x_2 - 6x_3& \\ & x_4 = \quad4-x_1 - x_2 -x_3 &\\ &x_5 =\quad2 - x_1&\\ &x_6=\quad3 - x_3&\\ & x_7=\quad6 - 3x_2 - x_3&\\ \end{alignat} \] 我们发现,对于B、C就是一样的,而A取决于基本变量和非基本变量,非基本变量符号相反,基本变量符号相同。
接着以最开始的线性规划求解过程的第二步为例,来看看我们的矩阵是如何进行运算的,第二步我们的结果如下(我们选择了\(x_1\)为替入变量,\(x_5\)为替出变量): \[ \begin{alignat}{4} &z = \quad-2 -14x_2 - 6x_3 + x_5& \\ & x_4 = \quad2 - x_2 -x_3 +x_5&\\ &x_1 =\quad2 - x_5&\\ &x_6=\quad3 - x_3&\\ & x_7=\quad6 - 3x_2 - x_3&\\ \end{alignat} \] 首先看看约束条件的式子,\(x_1 = 2 - x_5\)我们改写成: \(2 = x_1 + x_5\) , 因此这行矩阵就是: (b,a1,a2.....a7) = (2,1,0,0,0,1,0,0),其它的类推,注意-z,因此我们的矩阵应该是如下形式的: \[ \begin{equation} S_2 = \left( \begin{array}{c} 2& 0 & -14 & -6& 0 &1 &0 &0\\ 2& 0 & 1 & 1& 1 &-1 &0 &0\\ 2& 1 & 0 & 0& 0 &1 &0 &0\\ 3& 0 & 0 & 1& 0 &0 &1 &0\\ 6& 0 & 3 & 1& 0 &0 &0 &1\\ \end{array} \right) \end{equation} \] OK,那么\(S_1\) 如何变成\(S_2\)的?
首先是第2行,我们是将 \(x_1\)用\(x_5\)表示(\(x_1= x_5\)),在等式的变换中,就是移项,然后每一个都除以\(x_1\)的系数。其实用矩阵很简单,这里就是mat[2] /= mat[2][1] ,表示矩阵第二行都除以第二行第一个元素
其它行呢?只要有\(x_1\)的,我们都用\(x_1 = 2- x_5\)来表示,就是其它行的\(x_1\)的系数 * mat[2],然后相减,mat[i]= mat[i] - mat[2] * mat[i][1] ,这样就实现了约束条件中替入和替出变量的替换!比如第一行,就是mat[1] = mat[1] - mat[2] * 1变成两行直接相减
现在来看目标函数,对于目标函数,我们也是将\(x_1\)用 \(2 - x_5\)来表示,参照上面的思路,同样的减法:mat[0] = mat[0] - mat[2] * -1 = mat[0] + mat[2]。注意到我们的其实我们的z = -2,而左上角的为 2,也就是-z,这就是我们为啥说左上角是-z的原因。
用矩阵的形式来表示后,可以写出simplex beta0.99代码(去除版权信息、空行等,只需要21行!):
1 | # -*- coding: utf-8 -*- |
一个调用的例子:
"""
minimize -x1 - 14x2 - 6x3
st
x1 + x2 + x3 <=4
x1 <= 2
x3 <= 3
3x2 + x3 <= 6
x1 ,x2 ,x3 >= 0
answer :-32
"""
t = Simplex([-1, -14, -6])
t.add_constraint([1, 1, 1], 4)
t.add_constraint([1, 0, 0], 2)
t.add_constraint([0, 0, 1], 3)
t.add_constraint([0, 3, 1], 6)
print(t.solve())
print(t.mat)首先初始化目标函数,然后不断的使用add_constraint添加约束条件。
注意在上面的Simplex类中,我们在初始化中加入了参数max_mode,处理最大值的情况。
然后在16~18行中,我们初始化了最开始的基本变量为B, 需要松弛的变量有m-1个,合并(m-1) *( m-1)的一个对角阵和一行有m-1个0的数组(这是目标函数),然后将他们和原来的合并起来,这样就构成了我们的S矩阵。
19行判断是否还有元素可以继续被增大(就是系数为负)
20-22行选择合适的替入和替出变量,若无替出变量,说明原问题无界,我们在23行处理了这种情况。
24~27就是旋转的过程,进行矩阵的行变换。并用B数组记录替入的替入变量。
28行我们返回目标值z,若为最小值,则要*-1,最大值则不用(因为一开始已经*-1了)。然后最后对应x的解就是基本变量为对应的\(b_i\),非基本变量为0,注意删除我们松弛添加的变量(所以只要判断下标是否 < n)
simplex 0.99 beta 就是这么少的代码这么容易的就实现了!
来,跟我一起喊:python 大法好!
初始解 ≠ 基本可行解以及无解的情况
在你高呼python大法好的时候,!
但是我把它称为beta 0.99版本肯定是有原因的,绝大多数情况下,初始解就是基本可行解,但是也有例外啊!
而且还有无解的情况。(╯‵□′)╯︵┻━┻
栗子
栗子1
栗子1登场: \[ \begin{alignat}{2} \min\quad &x_1 + 2x_2& \\ \mbox{s.t.}\quad &x_1 + x_2 &\leq{2} \\ &x_1 + x_2 & \geq{1}\\ &x_1, \quad x_2 &\geq{0} &\\ \end{alignat} \] 首先转化为标准形式(>= 改成 <=, *-1),然后再转化为松弛形式: \[ \begin{alignat}{2} \min\quad &x_1 + 2x_2& \\ \mbox{s.t.}\quad & x_3 = 2 - x_1 - x_2 \\ &x_4 = -1 + x_1 + x_2\\ &x_1, \quad x_2 , \quad x_3 , \quad x_4 \geq{0} \\ \end{alignat} \] 而我们假设的非基本变量全为0,于是有:\((x_1,x_2,x_3,x_4) = (0,0,2,-1)\),但是\(x_4= -1\)是不满足条件的。即初始解不是基本可行解。
栗子2
再比如下面的例子(栗子2): \[ \begin{alignat}{2} \min\quad &x_1 + 2x_2& \\ \mbox{s.t.}\quad &x_1 + x_2 &\geq{2} \\ &x_1 + x_2 & \leq{1}\\ &x_1, \quad x_2 &\geq{0} &\\ \end{alignat} \] 其实这个例子就是例子1改变了个符号而已,但是要>=2,然后又要<=1的情况,这个例子显然是无解的。
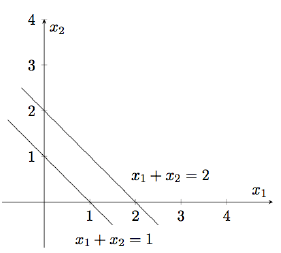
我们来看看初始解的情况,继续转化为标准形式,然后再转化为松弛形式: \[ \begin{alignat}{2} \min\quad &x_1 + 2x_2& \\ \mbox{s.t.}\quad & x_3 = -2 + x_1 + x_2 \\ &x_4 = 1 - x_1 - x_2\\ &x_1, \quad x_2 , \quad x_3 , \quad x_4 \geq{0} \\ \end{alignat} \] 同样的,非基本变量全为0,于是有 \((x_1,x_2,x_3,x_4) = (0,0,-2,1)\),但是\(x_3 = -2\)是不满足条件的。即初始解不是基本可行解。
simplex beta0.99测试
在上面的两个例子中,用我们的simplex beta0.99跑有啥结果呢?
第1个栗子,第一个矩阵为初始的矩阵,接下来是结果和对应的x1,x2值,然后是最后的矩阵
[[ 0. 1. 2. 0. 0.] [-1. -1. -1. 1. 0.] [ 2. 1. 1. 0. 1.]] (-0.0, {}) [[ 0. 1. 2. 0. 0.] [-1. -1. -1. 1. 0.] [ 2. 1. 1. 0. 1.]]
可以看到,由于c >=0,直接不迭代了,而这个问题用GLPK计算,正确的结果应该为:\(z = 1, x_1 = 1\)
第2个栗子:格式同上,结果如下
[[ 0. 1. 2. 0. 0.] [-2. -1. -1. 1. 0.] [ 1. 1. 1. 0. 1.]] (-0.0, {}) [[ 0. 1. 2. 0. 0.] [-2. -1. -1. 1. 0.] [ 1. 1. 1. 0. 1.]]
这个应该是无解的。
初始化
从上面的例子中,simplex beta 0.99 可以说是错误的! simplex beta 0.99产生错误的原因就是总把初始解当作基本可行解!
拍拍,打脸( ̄ε(# ̄)
那么如何做才是正确的呢?
问题回到我们的单纯形算法的第一步:找到一个初始的基本可行解。如何找?
我们首先思考上面的问题为什么会不可行。原因就是因为有\(b_i < 0\)!
因此,对于一个线性规划问题,有如下的情况:
- 若所有的\(b_i >=0\),说明初始的基本解就是基本可行解,在这种情况下,simplex beta 0.99是正确的。
- 若有\(b_i < 0\), 我们需要进行初始化操作,判断其是否有解(如栗子2),并返回一个基本可行解,然后运行simplex beta 0.99
第一种情况就是之前讨论的,这里讨论第二种情况。
以第一个栗子为例,构造辅助线性规划(auxiliary linear program)如下: \[ \begin{alignat}{2} \min\quad &x_0& \\ \mbox{s.t.}\quad &x_1 + x_2 - x_0&\leq&{2} \\ &-x_1 - x_2 - x_0 & \leq&{-1}\\ &x_1, \quad x_2,\quad x_0 &\geq{0} &\\ \end{alignat} \] 然后求解这个辅助线性规划\(L_{aux}\),如果\(L_{aux}\)的最优解\(x_0\)为0的话,说明这个原线性方程组有解。
下面是算法导论的证明,它证明的是最大化 \(x_0\) 和我们最小化x\(x_0\) 是一样的。

把\(L_{aux}\) 写成松弛形式:
\[ \begin{alignat}{2} & z = x_0 \\ &x_3 = 2 - x_1 - x_2 + x_0 \\ &x_4 = -1 + x_1 + x_2 + x_0\\ &x_1, \quad x_2,\quad x_3,\quad x_4,\quad x_0 &\geq{0} &\\ \end{alignat} \]
注意到这个初始解\((x_1,x_2,x_3,x_4,x_0) = (0,0,2,-1,0)\) 也不是基本可行解。现在马上就可以看到引入\(x_0\)的原因了,我们把\(x_0\)做为替入变量,选一个b最小的那一行的基本变量作为替出变量(这里是\(x_4\)),进行一次旋转操作,得:
\[ \begin{alignat}{2} &z = 1 - x_1 - x_2 + x_4\\ &x_3 = 2 - x_1 - x_2 + x_0 \\ &x_0 = 1 - x_1 - x_2 + x_4\\ \end{alignat} \]
进行旋转之后,初始解\((x_1,x_2,x_3,x_4,x_0)\) 变为 (0,0,2,0,1),这就是因为\(x_0\) 的替入 ,使得所有的b >=0
有人可能会问,上面的例子中,只有一个负的,多个负的怎么办?还能保证么?
答案是可以的,因为我们选择替出的是\(b_i\) 为负的最小的那一行的基本变量,而一开始,我们构建辅助函数时,\(x_0\)的系数为-1,因此,旋转的时候,矩阵运算相当于其它每一行减去这一行,而b为负,负负得正,必然最后所有的b都>=0。
现在,我们已经有一个基本可行解了,我们求解这个辅助线性规划即可。
和上面的思想一样,这里要么增大\(x_1\), 要么增大\(x_2\),假设选择\(x_1\),然后第二个等式有最严格的限制,选择\(x_0\)为替出变量,得 \(x_1 = 1 - x_2 + x_4 - x_0\) \[ \begin{alignat}{2} &z = x_0\\ &x_3 = 1 - x_4 + 2x_0 \\ &x_1 = 1 - x_2 + x_4 - x_0\\ \end{alignat} \]
此时,基本解为:\((x_1,x_2,x_3,x_4,x_0)= (1,0,1,0,0)\), 此时\(z = x_0 = 0\),无法继续增大某个变量使得z继续减少,因此此时为最优解,就是z =0,说明原问题有解。
接下来,我们要恢复原问题的目标函数,就是用现在的基本变量替代原目标函数中的基本变量(若\(x_0\)是基本变量,那就要旋转去掉它),此外由于\(x_0 = 0\),因此可以将其去掉:
\[ \begin{alignat}{2} &z &=& \quad x_1 + 2x_2 \\ & &=& \quad 1 + x_2 + x_4 - x_0\\ & &=& \quad 1 + x_2 + x_4\\ \end{alignat} \]
其它的约束条件同理去掉\(x_0\)可得:
\[ \begin{alignat}{2} &z = 1 + x_2 + x_4\\ &x_3 = 1 - x_4 \\ &x_1 = 1 - x_2 + x_4\\ \end{alignat} \]
因此,现在,我们通过构造了一个辅助线性规划Laux 将原来的问题转化为上面的线性规划,并且它的初始解就是基本可行解:\((x_1,x_2,x_3,x_4 = (1,0,1,0)\),然后求解这个新的线性规划即可。
我们很幸运的发现(其实是博主偷懒举了个简单的例子(✿◡‿◡)),这里无法通过增大任何的变量使得目标值变小,因此此时就是结果啦,而\((x_1,x_2,x_3,x_4 = (1,0,1,0)\)就是最后的解,z = 1。
下面总结一下上面的过程,
- 若bi都大于等于0 跳到9
- 引入\(x_0\),创建一个辅助线性规划\(L_{aux}\)
- 将\(L_{aux}\)写成松弛形式
- 选择\(b_i\)最小的那一行的基本变量为替出变量,\(x_0\)为替入变量,进行一次旋转操作
- 求解\(L_{aux}\)
- 若\(L_{aux}\)的最优解为0,那么原问题有解,否则无解,return "no answer"
- 在有解的情况下,若\(x_0\)为基本解,那么执行一次旋转,把它变为非基本变量
- 恢复原始的目标函数,但是将其基本变量替换掉
- 运行simplex beta 0.99 对新的线性规划方程求解。
PS:有兴趣的读者可以计算一下例子2,会发现辅助函数的最优解不是0,而是0.5,说明无解
完整的单纯形算法
结合simplex beta 0.99和初始化的过程,可以写成如下的simplex 1.0代码(去除版权信息,空行等,也只要40行左右,还是简洁^ ^)
1 | # -*- coding: utf-8 -*- |
上面的代码中,将旋转操作独立为一个方法(23~27),将单纯形算法的核心也独立为一个方法(14~21),这是考虑到要多次调用的原因,并且代码之前的几乎没什么变化,这里不做过多的解释。
主要变化在于solve方法,30~32和之前是一样的,不解释 ♪(^ ∇^*)
33行判断是否有一个b < 0 ?如果有,说明初始解不可行。否则直接执行45行,调用单纯形算法
34~44处理的是不可行的情况,
- 34:首先找一个最小b的下标
- 35和36作用在于保存原来的目标函数,并将第0行设为0,然后添加\(x_0\) 需要拼接矩阵,其实就是构造辅助线性规划\(L_{aux}\)
- 37执行旋转操作,使其初始解可行
- 38行求解\(L_{aux}\) 最优值是否为0,是就是有解,否则无解
- 40-41行若最后的\(x_0\)是基本解,找一个第0行不是0的元素作为替入变量,将x0替出
- 42~44 恢复初始目标函数,删除\(x_0\)那一列,并且替换目标函数中的基本变量。
好了,代码还是很短,其实能更短,但是会影响可读性!
再来高呼: Python 大法好!
从几何角度看单纯形算法
上面我们介绍单纯形算法的时候,是通过最直观的等式变换(就是旋转操作)介绍的。
我们知道,线性规划就是在可行域围成的多胞形中求解,现在从几何的视图来看看单纯形算法。
只需考虑顶点
让我再次召唤之前的图:
直观上看,最优解就在顶点上,不需要考虑内部点。
一个引入的证明
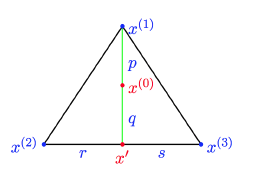
我们假设\(x^{(0)}\)是最优解,连接\(x^{(1)}\)和\(x^{(0)}\)与 \(x^{(2)}\)和\(x^{(3)}\)相交于点x'
我们可以把\(x^{(0)}\)分解,\(x^{(0)} = λ_1 x^{(1)} + (1 - λ_1)x'\) 其中\(λ_1 = p / (p + q)\)
同样的把x‘ 分解,\(x'= λ_2 x^{(2)} + (1 - λ_2)x^{(3)}\)其中\(λ_2 = r / (r + s)\)
因此有:\(x^{(0)} = λ_1 x^{(1)} + (1 - λ_1)λ_2 x^{(2)} + (1 - λ_1) (1 - λ_2)x^{(3)}\),而\(λ_1 + (1 - λ_1)λ_2 + (1 - λ_1) (1 - λ_2) = 1\)
设 \(c^Tx^{(1)}\) 小于等于 \(c^T x^{(2)}\), \(c^Tx^{(3)}\),因此有: \[ \begin{alignat}{2} C^Tx^{(0)} &=λ_1 C^T x^{(1)} + (1 - λ_1)λ_2 C^T x^{(2)} + (1 - λ_1) (1 - λ_2) C^T x^{(3)} \\ & \geq λ_1 C^T x^{(1)} + (1 - λ_1)λ_2 C^T x^{(1)} + (1 - λ_1) (1 - λ_2) C^T x^{(1)}\\ & =C^Tx^{(1)} \end{alignat} \] 因此,\(x^{(1)}\) 并不比\(x^{(0)}\)差。
我们可以推广到更多的情况。(见附件的68页)
多边形的顶点等价于矩阵的基
上面提到,最优解一定在顶点上,我们不需要考虑内部的点。
那么,如何获得顶点呢?
可以证明,顶点就是基,基就是顶点。(见附件的72-78页)
我们只需要找到矩阵的基就好了。
顶点的游走
我们知道,多边形的顶点就是基,且最优解在顶点上,我们需要做的就是,按照一定的规则沿着边遍历顶点,直到不能更新了为止。
如何从一个顶点到另一个顶点?更新到什么时候为止?
我们先讨论第一个问题。
还是一开始介绍单纯形算法的例子: \[ \begin{alignat}{2} \min\quad &-x_1 -14x_2 - 6x_3& \\ \mbox{s.t.}\quad &x_1 + x_2 +x_3 + x_4 \quad \quad \quad \quad \quad \quad \quad &=& \quad4&\\ &x_1 \quad \quad \quad \quad \quad \quad \quad+x_5 \quad \quad\quad \quad\quad&=&\quad2&\\ & \quad\quad \quad \quad\quad x_3 + \quad \quad \quad \quad + x_6&=&\quad3&\\ & \quad \quad 3x_2 + x_3\quad\quad \quad \quad\quad \quad \quad +x_7&=&\quad6&\\ &x_1, \quad x_2 ,\quad x_3, \quad x_4, \quad x_5 ,\quad x_6, \quad x_7\quad &\quad\geq{0} &\\ \end{alignat} \] 其松弛条件系数A,目标函数系数C,用矩阵表示为: \[ \begin{equation} %开始数学环境 C = \left( %左括号 \begin{array}{c} -1 & -14 & -6& 0 &0 &0 &0\\ %第一行元素 \end{array} \right) %右括号 \\ \quad \\ B =\left( \begin{array}{c} 4\\ 2\\ 3\\ 6\\ \end{array} \right) \quad A =\left( %左括号 \begin{array}{c} %c为居中放置 1 & 1 & 1& 1 &0 &0 &0\\ %第一行元素 1 & 0 & 0& 0 &1 &0 &0\\ %第二行元素 0 & 0 & 1& 0 &0 &1 &0\\ %第三行元素 0 & 3 & 1& 0 &0 &0 &1\\ %第四行元素 \end{array} \right) %右括号 \end{equation} \] 这里假设我们初始的解X设为\((x_1,x_2,x_3 ,x_4 ,x_6,x_7) = (0,0,0,4,2,3,6)\).就是我们的初始在(0,0,0)的点上。
我们的初始点用红点来表示,而绿色的线就是我们下一步走的边,如下图所示:
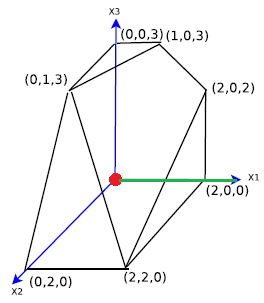
要实现图中绿色的边,如何做呢?
其实就是之前旋转的操作!想想我们之前的旋转,我们要选择\(x_1\)为替入变量,\(x_5\)为替出变量,然后执行旋转。 (忘记的翻回去看,这里不赘述)然后就得到新的基本解及其值为:\((x_1,x_2....x_7) = (2,0,0,2,0,3,6)\)。注意,这时候我们已经到达新的点了!可以说就是沿着那条边走的!
可以说,设边的方向为λ,我们沿着边走的距离是θ,那么,我们走的就是\(x ' = x - θλ\)。
那么λ是什么呢?其实就是选择一个非基的列向量。
为了说明,我们用\(a_1 .. a_7\) 来表示矩阵A的对应的列: \[ \begin{equation} A =\left( \begin{array}{c} 1 & 1 & 1& 1 &0 &0 &0\\ 1 & 0 & 0& 0 &1 &0 &0\\ 0 & 0 & 1& 0 &0 &1 &0\\ 0 & 3 & 1& 0 &0 &0 &1\\ \end{array} \right) \end{equation} \] 可以看到非基向量可以用基向量表示,比如这里\(a_1 = 1a_4 + 1a_5 + 0a_6 + 0a_7\)也就是 \(-a_1+ 0a_2 + 0a_3 + 1a_4 + 1a_5 + 0a_6 + 0a_7 = 0\)
我们的λ 也就等于这个系数,就是\(λ = (-1,0,0,1,1,0,0)\)
那么走多少呢?走过多会超出区域,过少会达不到顶点,答案就是2!想想我们之前选\(x_5\)的原因:\(x_5\)最大程度的限制了\(x_1\)的值, \(x_1 <= 2\),于是我们定义θ就是限制最紧的值。换句话说,在S矩阵中,就是\(bi / x[i][1]\)最小的值(θ > 0)。
让我们验算一下:
(0,0,0,4,2,3,6) - 2 * (-1,0,0,1,1,0,0) = (2,0,0,2,0,3,6) ! (o゜▽゜)o☆[BINGO!] 和之前的完全一样!
我们做一次旋转的操作,其实就是一个顶点到另一个顶点的过程!很神奇吧!
仔细思考一下为什么之前的旋转等价于这里的非基向量表示的边?
我们用原来的基向量\((a_4,a_5,a_6,a_7)\) 来表示\(a_1\),其实可以换个角度想想之前的等式变换,我们在这里表示\(a_1\)可以认为是之前的将每行有\(x_1\)带入的过程。\(a_1\)上为1,说明这一行有\(x_1\),我们需要带入。
停止条件
现在,我们已经在顶点上,然后沿着边游走了,那么,我们游走到什么时候为止呢?
注意,我们的目标是最小化目标函数,即求\(\min C^Tx\)
假设我们从x沿着边到达x',我们有: \(x' = x - \theta \lambda\),我们的λ形式为:\([λ_1,λ_2,.....,-1,.....λ_m]\)那么目标函数的值增加了:\(C^Tx' - C^Tx = - θC^Tλ = -θ(-c_e + Σλ_ic_i) = θ(c_e - Σλ_ic_i)\) 其中,最后的求和符号是对e替入前的基向量求和的。由于θ >0 ,因此\(c_e - Σλ_ic_i >=0\) 说明我们可以停止了(x比x'不差)。我们把\(c_e - Σλ_ic_i\) 称为检验数(checking number)
我们把检验数写成矩阵的形式就是:\(C^T - C^{T_B} B^{-1}A\) (\(C^{T_B}\)为基向量的C的转置)。
下面证明对于顶点x,若检验数 \(C^T - C^{T_B} B^{-1}A >=0\) ,则x为最优解。
设y 为其它任意的可行解, 于是有Ay = b, y>=0
\(C^T y \ge C^{T_B} B^{-1}Ay = C^{T_B} B^{-1}b = C^{T_B} X_B = C^Tx.\)
就是说,其它的可行解y不比x好
注意我们旋转的过程中,\(C^{T_B}=0\),或者说\(Σλ_ic_i = 0\) 因此,若\(C_N\)(非基的那些) 都 >=0 ,就可以停止了。这和之前的其实还是一样的。
小结
用几何的角度看待单纯形算法,主要有几点:
- 最优解可以在顶点上找到,不需考虑内部点
- 顶点 <=> 矩阵的基
- 一次旋转就是一个顶点沿着一条边λ走θ倍到另一个顶点的过程
- 当我们的检验数 >=0 停止迭代
当然也需要注意初始化单纯形算法,比如之前的情况:
我们的顶点要在可行域才行,而不要跑到(0,0)去了。初始方法和之前的一样。
时间复杂度
现在,来讨论一下单纯形算法的时间复杂度吧。
在之前的算法中,我们每一次查找一个 负数cx需要O(N),(这里用N为了区分代码中的N,这里N = m + n)并且查找最小的θ所在的row需要O(m),然后执行旋转,在旋转中,我们对于i!=row的执行mat[i]= mat[i] - mat[row] * mat[i][col],需要O(m*N)
因此一次的复杂度为O(m*N)
1 | def _simplex(self, mat, B, m, n): |
那么执行多少次呢?假设为k次就是O(kmN)
在绝大多数的情况下,单纯形算法也都是多项式时间的算法,自从1949年单纯形算法提出后,人们也一度的以为它就是多项式时间的,直到有人出来挑事情。。。。(╯‵□′)╯︵┻━┻
V. Klee and G. L. Minty[1972] 构造了一个例子: \[ \begin{alignat}{2} \max\quad &x_n& \\ \mbox{s.t.}\quad & δ &\leq&\quad{x_i}\quad &\leq&{1}&for\quad i=1...n \\ & δx_{i-1}&\leq&\quad{x_i}\quad&\leq&1 -δx_{i-1} \quad&for\quad i=2...n \\ & &&\quad x_i &\geq&{0} &for\quad i=1...n\\ \end{alignat} \]
在这个例子中,单纯形算法将会遍历2n个顶点。这个例子提出,说明单纯形算法不是一个多项式时间复杂度的算法。但是为什么它实际运行时是多项式时间复杂度的?这个问题困扰了人们很久,直到2001年 Daniel A. Spielman 和 Shang-Hua Teng 提出了平滑型复杂度理论(smoothed complexity),完美的解决了这个问题。
- Average-case analysis was first introduced to overcome the limitations of worst-case analysis, however the difficulty is saying what an average case is. The actual inputs and distribution of inputs may be different in practice from the assumptions made during the analysis.
- Smoothed analysis is a hybrid of worst-case and average-case analyses that inherits advantages of both, by measuring the expected performance of algorithms under slight random perturbations of worst-case inputs.
- The performance of an algorithm is measured in terms of both the input size, and the magnitude of the perturbations.
- If the smoothed complexity of an algorithm is low, then it is unlikely that the algorithm will take long time to solve practical instances whose data are subject to slight noises and imprecisions.
可能原值会是非多项式时间的,但是在真实世界中,基本都是真实数据+噪声的值,或者还要加上误差,因此单纯形算法“因祸得福”,一般为多项式时间的。不同于大家做信号处理或者图像处理时,将讨厌的噪声去掉,滕老师说:“噪声是个好东西”。
小结
给定一个线性规划L,就只有如下三种情形:
- 有一个有限目标值的最优解
- 不可行
- 无界
在本文中,我们对其三种情况都进行了讨论,如果有啥疑问或错误欢迎提出。 ^ ^
单纯形算法本身并不难,老师上课讲的是几何的角度,听得我一愣一愣的,之后看算法导论(就是最开始的等式变换),通熟易懂,但矩阵还是跟着老师的思路写的,然后对照两者的思路发现略有不同,让我纠结不已,觉得有必要整理一下~现在看来,其实这些方法都殊途同归。
然后,写这个blog累死了,用typora打latex,然后blog wordpress再转成图片(现在用mathjax直接支持latex公式拉),看了一下字数9000左右了 好累/(ㄒoㄒ)/~~
所以觉得好的话可以进行打赏 (逃

